Алгоритмы маршрутизации
Алгоритмы маршрутизации можно дифференцировать,
основываясь на нескольких ключевых характеристиках.
Во-первых, на работу результирующего протокола маршрутизации
влияют конкретные задачи, которые решает разработчик
алгоритма. Во-вторых, существуют различные типы алгоритмов
маршрутизации, и каждый из них по-разному влияет на сеть
и ресурсы маршрутизации. И наконец, алгоритмы маршрутизации
используют разнообразные показатели, которые влияют на
расчет оптимальных маршрутов. В следующих разделах
анализируются эти атрибуты алгоритмов маршрутизации.
Цели разработки алгоритмов маршрутизации
При разработке алгоритмов маршрутизации часто преследуют
одну или несколько из перечисленных ниже целей:
Библиографическая справка.
В общедоступном значении слова маршрутизация означает
передвижение информации от источника к пункту назначения
через об'единенную сеть. При этом, как правило, на пути
встречается по крайней мере один узел. Маршрутизация часто
противопоставляется об'единению сетей с помощью моста,
которое, в популярном понимании этого способа, выполняет
точно такие же функции. Основное различие между ними
заключается в том, что об'единение с помощью моста имеет
место на Уровне 2 эталонной модели ISO, в то время как
маршрутизация встречается на Уровне 3. Этой разницей об'ясняется
то, что маршрутизация и об'единение по мостовой схеме используют
различную информацию в процессе ее перемещения от
источника к месту назначения. Результатом этого является то,
что маршрутизация и об'единение с помощью моста выполняют
свои задачи разными способами; фактически, имеется
несколько различных видов маршрутизации и об'единения с
помощью мостов. Дополнительная информация об об'единении
сетей с помощью мостов приведена в
.
Тема маршрутизации освещалась в научной литературе о
компьютерах более 2-х десятилетий, однако с коммерческой
точки зрения маршрутизация приобрела популярность только в
1970 гг. В течение этого периода сети были довольно
простыми, гомогенными окружениями. Крупномасштабное
об'единение сетей стало популярно только в последнее время.
Коммутация
Алгоритмы коммутации сравнительно просты и в основном
одинаковы для большинства протоколов маршрутизации. В
большинстве случаев главная вычислительная машина
определяет необходимость отправки пакета в другую главную
вычислительную машину. Получив определенным способом адрес
роутера, главная вычислительная машина-источник
отправляет пакет, адресованный специально в физический адрес
роутера (уровень МАС), однако с адресом протокола
(сетевой уровень) главной вычислительной машины пункта
назначения.
После проверки адреса протокола пункта назначения пакета
роутер определяет, знает он или нет, как передать
этот пакет к следующему роутеру. Во втором
случае (когда роутер не знает, как переслать пакет)
пакет, как правило, игнорируется. В первом случае
роутер отсылает пакет к следующей роутеру
путем замены физического адреса пункта назначения на
физический адрес следующего роутера и последующей передачи
пакета.
Следующая пересылка может быть или не быть
главной вычислительной машиной окончательного пункта
назначения. Если нет,то следующей пересылкой, как правило,
является другой роутер, который выполняет такой же
процесс принятия решения о коммутации. По мере того, как
пакет продвигается через об'единенную сеть, его физический
адрес меняется, однако адрес протокола остается неизменным.
Этот процесс иллюстрируется на Рис. 2-2.

В изложенном выше описании рассмотрена коммутация между
источником и системой конечного пункта назначения. Международная
Организация по Стандартизации (ISO) разработала
иерархическую терминологию, которая может быть полезной при
описании этого процесса. Если пользоваться этой
терминологией, то устройства сети, не обладающие
способностью пересылать пакеты между подсетями, называются
конечными системами (ЕS), в то время как устройства сети,
имеющие такую способность, называются промежуточными
системами (IS). Промежуточные системы далее подразделяются на
системы, которые могут сообщаться в пределах "доменов
мааршрутизации" ("внутридоменные" IS), и системы, которые
могут сообщаться как в пределах домена маршрутизации, так и
с другими доменами маршрутизации ("междоменные IS"). Обычно
считается, что "домен маршрутизации" - это часть
об'единенной сети, находящейся под общим административным
управлением и регулируемой пределенным набором
административных руководящих принципов. Домены маршрутизации
называются также "автономными системами" (AS). Для
опрелеленных протоколов домены маршрутизации могут быть
дополнительно подразделены на "участки маршрутизации",
однако для коммутации как внутри участков, так и между ними
также используются внутридоменные протоколы маршрутизации.
Компоненты маршрутизации
Маршрутизация включает в себя два основных компонента:
определение оптимальных трактов маршрутизации и
транспортировка информационых групп (обычно называемых
пакетами) через об'единенную сеть. В настоящей работе
последний из этих двух компонентов называется коммутацией.
Коммутация относительно проста. С другой стороны,
определение маршрута может быть очень сложным процессом.
Определение маршрута
Определение маршрута может базироваться на
различных показателях (величинах, результирующих из
алгоритмических вычислений по отдельной переменной -
например, длина маршрута) или комбинациях показателей.
Программные реализации алгоритмов маршрутизации высчитывают
показатели маршрута для определения оптимальных маршрутов к
пункту назначения.
Для облегчения процесса определения маршрута, алгоритмы
маршрутизации инициализируют и поддерживают таблицы
маршрутизации, в которых содержится маршрутная информация.
Маршрутная информация изменяется в зависимости от
используемого алгоритма маршрутизации.
Алгоритмы маршрутизации заполняют маршрутные таблицы
неким множеством информации. Ассоциации
"Пункт назначения/следующая пересылка" сообщают
роутеру, что определенный пункт назначения может быть
оптимально достигнут путем отправки пакета в определенный
роутер, представляющий "следующую пересылку" на пути
к конечному пункту назначения. При приеме поступающего
пакета роутер проверяет адрес пункта назначения и
пытается ассоциировать этот адрес со следующей пересылкой.
На рис. 2-1 приведен пример маршрутной таблицы
"место назначения/следующая пересылка".
| 27 | Node A |
| 57 | Node B |
| 17 | Node C |
| 24 | Node A |
| 52 | Node A |
| 16 | Node B |
| 26 | Node A |
| . . . | . . . |
Figure 2-1 Destination/Next Hop Routing Table
В маршрутных таблицах может содержаться также и другая
информация. "Показатели" обеспечивают информацию о
желательности какого-либо канала или тракта. Роутеры
сравнивают показатели, чтобы определить оптамальные
маршруты. Показатели отличаются друг oт друга в зависимости
от использованной схемы алгоритма маршрутизации. Далее в
этой главе будет представлен и описан ряд общих показателей.
Роутеры сообщаются друг с другом (и поддерживают
свои маршрутные таблицы) путем передачи различных сообщений.
Одним из видов таких сообщений является сообщение об "обновлении
маршрутизации". Обновления маршрутизации обычно включают всю
маршрутную таблицу или ее часть. Анализируя информацию об
обновлении маршрутизации, поступающую ото всех
роутеров, любой из них может построить детальную
картину топологии сети. Другим примером сообщений, которыми
обмениваются роутеры, является "об'явление о состоянии
канала". Об'явление о состоянии канала информирует другие
роутеры о состоянии кааналов отправителя. Канальная
информация также может быть использована для построения
полной картины топологии сети. После того, как топология
сети становится понятной, роутеры могут определить
оптимальные маршруты к пунктам назначения.
Оптимальность Оптимальность, вероятно
Алгоритмы маршрутизации могут быть классифицированы по
типам. Например, алгоритмы могут быть:
Статические или динамические алгоритмы
Статические алгоритмы маршрутизации вообще вряд ли
являются алгоритмами. Распределение статических таблиц
маршрутизации устанавливется администратором сети до начала
маршрутизации. Оно не меняется, если только администратор
сети не изменит его. Алгоритмы, использующие статические
маршруты, просты для разработки и хорошо работают в
окружениях, где трафик сети относительно предсказуем, а схема
сети относительно проста.
Т.к. статические системы маршрутизации не могут
реагировать на изменения в сети, они, как правило, считаются
непригодными для современных крупных, постоянно изменяющихся
сетей. Большинство доминирующих алгоритмов маршрутизации
1990гг. - динамические.
Динамические алгоритмы маршрутизации подстраиваются к
изменяющимся обстоятельствам сети в масштабе реального
времени. Они выполняют это путем анализа поступающих сообщений
об обновлении маршрутизации. Если в сообщении указывается,
что имело место изменение сети, программы маршрутизации
пересчитывают маршруты и рассылают новые сообщения
о корректировке маршрутизации. Такие сообщения пронизывают
сеть, стимулируя роутеры заново прогонять свои
алгоритмы и соответствующим образом изменять таблицы
маршрутизации. Динамические алгоритмы маршрутизации могут дополнять
статические маршруты там, где это уместно. Например, можно
разработать "роутер последнего обращения" (т.е.
роутер, в который отсылаются все неотправленные по
определенному маршруту пакеты). Такой роутер выполняет
роль хранилища неотправленных пакетов, гарантируя, что все
сообщения будут хотя бы определенным образом обработаны.
Одномаршрутные или многомаршрутные алгоритмы
Некоторые сложные протоколы маршрутизации обеспечивают
множество маршрутов к одному и тому же пункту назначения.
Такие многомаршрутные алгоритмы делают возможной
мультиплексную передачу трафика по многочисленным линиям;
одномаршрутные алгоритмы не могут делать этого. Преимущества
многомаршрутных алгоритмов очевидны - они могут обеспечить
заначительно большую пропускную способность и надежность.
Одноуровневые или иерархические алгоритмы
Некоторые алгоритмы маршрутизации оперируют в плоском
пространстве, в то время как другие используют иерархиии
маршрутизации. В одноуровневой системе маршрутизации все
роутеры равны по отношению друг к другу. В
иерархической системе маршрутизации некоторые роутеры
формируют то, что составляет основу (backbone - базу) маршрутизации.
Пакеты из небазовых роутеров перемещаются к
базовыи роутерам и пропускаются через них до тех пор,
пока не достигнут общей области пункта назначения. Начиная с
этого момента, они перемещаются от последнего базового
роутера через один или несколько небазовых
роутеров до конечного пункта назначения.
Системы маршрутизации часто устанавливают логические
группы узлов, называемых доменами, или автономными системами
(AS), или областями. В иерархических системах одни
роутеры какого-либо домена могут сообщаться с
роутерами других доменов, в то время как другие роутеры
этого домена могут поддерживать связь с роутеры только
в пределах своего домена. В очень крупных сетях могут существовать
дополнительные иерархические уровни. Роутеры
наивысшего иерархического уровня образуют базу
маршрутизации.
Основным преимуществом иерархической маршрутизации
является то, что она имитирует организацию большинства
компаний и следовательно, очень хорошо поддерживает их схемы
трафика. Большая часть сетевой связи имеет место в пределах
групп небольших компаний (доменов). Внутридоменным
роутерам необходимо знать только о других
роутерах в пределах своего домена, поэтому их
алгоритмы маршрутизации могут быть упрощенными.
Соответственно может быть уменьшен и трафик обновления
маршрутизации, зависящий от используемого алгоритма
маршрутизации.
Алгоритмы с игнтеллектом в главной вычислительной машине или в роутере
Некоторые алгоритмы маршрутизации предполагают, что
конечный узел источника определяет весь маршрут. Обычно это
называют маршрутизацией от источника. В системах
маршрутизации от источника роутеры действуют просто
как устойства хранения и пересылки пакета, без всякий
раздумий отсылая его к следующей остановке.
Другие алгоритмы предполагают, что главные
вычислительные машины ничего не знают о маршрутах. При
использовании этих алгоритмов роутеры определяют
маршрут через об'единенную сеть, базируясь на своих
собственных расчетах. В первой системе, рассмотренной выше,
интеллект маршрутизации находится в главной вычислительной
машине. В системе, рассмотренной во втором случае,
интеллектом маршрутизации наделены роутеры.
Компромисс между маршрутизацией с интеллектом в главной
вычислительной машине и маршрутизацией с интеллектом в
роутере достигается путем сопоставления оптимальности
маршрута с непроизводительными затратами трафика. Системы с
интеллектом в главной вычислительной машине чаще выбирают
наилучшие маршруты, т.к. они, как правило, находят все
возможные маршруты к пункту назначения, прежде чем пакет
будет действительно отослан. Затем они выбирают наилучший
мааршрут, основываясь на определении оптимальности данной
конкретной системы. Однако акт определения всех маршрутов
часто требует значительного трафика поиска и большого об'ема
времени.
Внутридоменные или междоменные алгоритмы
Некоторые алгоритмы маршрутизации действуют только в
пределах доменов; другие - как в пределах доменов, так и
между ними. Природа этих двух типов алгоритмов различная.
Поэтому понятно, что оптимальный алгоритм внутридоменной
маршрутизации не обязательно будет оптимальным алгоритмом
междоменной маршрутизации.
Алгоритмы состояния канала или вектора расстояния
Алгоритмы состояния канала (известные также как
алгоритмы "первоочередности наикратчайшего
маршрута") направляют потоки маршрутной информации во все
узлы об'единенной сети. Однако каждый роутер посылает
только ту часть маршрутной таблицы, которая описывает
состояние его собственных каналов. Алгоритмы вектора
расстояния ( известные также как алгоритмы Бэлмана-Форда)
требуют от каждогo роутера посылки всей или части
своей маршрутной таблицы, но только своим соседям. Алгоритмы
состояния каналов фактически направляют небольшие
корректировки по всем направлениям, в то время как алгоритмы
вектора расстояний отсылают более крупные корректировки
только в соседние роутеры.
Отличаясь более быстрой сходимостью, алгоритмы
состояния каналов несколько меньше склонны к образованию
петель маршрутизации, чем алгоритмы вектора расстояния. С
другой стороны, алгоритмы состояния канала характеризуются
более сложными расчетами в сравнении с алгоритмами вектора
расстояний, требуя большей процессорной мощности и памяти,
чем алгоритмы вектора расстояний. Вследствие этого,
реализация и поддержка алгоритмов состояния канала может
быть более дорогостоящей. Несмотря на их различия, оба
типа алгоритмов хорошо функционируют при самых различных
обстоятельствах.
Показатели алгоритмов (метрики)
Маршрутные таблицы содержат информацию, которую
используют программы коммутации для выбора наилучшего
маршрута. Чем характеризуется построение маршрутных таблиц?
Какова особенность природы информации, которую они содержат?
В данном разделе, посвященном показателям алгоритмов,
сделана попытка ответить на вопрос о том, каким образом
алгоритм определяет предпочтительность одного маршрута по
сравнению с другими.
В алгоритмах маршрутизации используется много различных
показателей. Сложные алгоритмы маршрутизации при выборе
маршрута могут базироваться на множестве показателей,
комбинируя их таким образом, что в результате получается
один отдельный (гибридный) показатель. Ниже перечислены
показатели, которые используются в алгоритмах маршрутизации:
Длина маршрута
Длина маршрута является наиболее общим показателем
маршрутизации. Некоторые протоколы маршрутизации позволяют
администраторам сети назначать произвольные цены на каждый
канал сети. В этом случае длиной тракта является сумма
расходов, связанных с каждым каналом, который был
траверсирован. Другие протоколы маршрутизации определяют
"количество пересылок", т.е. показатель, характеризующий
число проходов, которые пакет должен совершить на пути от
источника до пункта назначения через изделия об'единения
сетей (такие как роутеры).
Надежность
Надежность, в контексте алгоритмов маршрутизации,
относится к надежности каждого канала сети (обычно
описываемой в терминах соотношения бит/ошибка). Некоторые
каналы сети могут отказывать чаще, чем другие. Отказы одних
каналов сети могут быть устранены легче или быстрее, чем
отказы других каналов. При назначении оценок надежности
могут быть приняты в расчет любые факторы надежности. Оценки
надежности обычно назначаются каналам сети администраторами
сети. Как правило, это произвольные цифровые величины.
Задержка
Под задержкой маршрутизации обычно понимают
отрезок времени, необходимый для передвижения пакета от
источника до пункта назначения через об'единенную сеть.
Задержка зависит от многих факторов, включая полосу
пропускания промежуточных каналов сети, очереди в порт
каждого роутера на пути передвижения пакета,
перегруженность сети на всех промежуточных каналах сети и
физическое расстояние, на которое необходимо переместить
пакет. Т.к. здесь имеет место конгломерация нескольких
важных переменных, задержка является наиболее общим и полезным
показателем.
Полоса пропускания
Полоса пропускания относится к имеющейся
мощности трафика какого-либо канала. При прочих равных
показателях, канал Ethernet 10 Mbps предпочтителен любой
арендованной линии с полосой пропускания 64 Кбайт/сек. Хотя
полоса пропускания является оценкой максимально достижимой
пропускной способности канала, маршруты, проходящие через
каналы с большей полосой пропускания, не обязательно
будут лучше маршрутов, проходящих через менее
быстродействующие каналы.
[]
[]
[]
Биографическая справка
Серийное изготовление мостов началось в начале 1980гг. В то
время, когда они появились, мосты о'единяли гомогенные сети,
делая возможным прохождение пакетов между ними. В последнее время
об'единение различных сетей с помощью мостов также было определено
и стандартизировано.
На первый план выдвинулись несколько видов об'единений с помощью
мостов. В окружениях Ethernet в основном встречается "transparent
bridging" (прозрачное соединение). В окружениях Token Ring в первую
очередь используется "Source-route bridging" (соединение маршрут-
источник). "Translational bridging" (трансляционное соединение)
обеспечивает трансляцию между форматами и принципами передачи
различных типов сред (обычно Ethernet и Token Ring). "Source-route
transparent bridging" (прозрачное соединение маршрут-источник)
об'единяет алгоритмы прозрачного соединения и соединения маршрут-
источник, что позволяет передавать сообщения в смешанных окружениях
Ethernet/Token Ring.
Уменьшающиеся цены на роутеры и введение во многие из
них возможности соединять по мостовой схеме, сделанное в последнее
время, значительно сократило долю рынка чистых мостов. Те мосты,
которые уцелели, обладают такими характеристиками, как сложные схемы
фильтрации, псевдоинтеллектуальный выбор маршрута и высокая
производительность. В то время как в конце 1980гг шли бурные дебаты
о преимуществах соединения с помощью мостов в сравнении с
роутерами, в настоящее время большинство пришло к выводу,
что часто оба устройства необходимы в любой полной схеме об'единения
сетей.
Основы технологии объединения сетей
Уровень, на котором находит применение об'единение с помощью
мостов (называемый канальным уровнем), контролирует поток информации,
обрабатывает ошибки передачи, обеспечивает физическую (в отличие от
логической) адресацию и управляет доступом к физической среде.
Мосты обеспечивают выполнение этих функций путем поддержки различных
протоколов канального уровня, которые предписывают определенный
поток информации, обработку ошибок, адресацию и алгоритмы доступа к
носителю. В качестве примеров популярных протоколов канального
уровня можно назвать Ethernet, Token Ring и FDDI.
Мосты - несложные устройства. Они анализируют поступающие фреймы,
принимают решение о их продвижении, базируясь на информации,
содержащейся в фрейме, и пересылает их к месту назначения. В некоторых
случаях (например, при об'единении "источник-маршрут") весь путь к
месту назначения содержится в каждом фрейме. В других случаях
(например, прозрачное об'единение) фреймы продвигаются к месту
назначения отдельными пересылками, по одной за раз. Дополнительная
информация по соединению источник-маршрут и прозрачному соединению
приведена соответственно в
главе 30
и
главе 29 .
Основным преимуществом об'единения с помощью мостов является
прозрачность протоколов верхних уровней. Т.к. мосты оперируют на
канальном уровне, от них не требуется проверки информации высших
уровней. Это означает, что они могут быстро продвигать
трафик, представляющий любой протокол сетевого уровня. Обычным
делом для моста является продвижение Apple Talk, DECnet, TCP/IP,
XNS и другого трафика между двумя и более сетями.
Мосты способны фильтровать фреймы, базирующиеся на любых полях
Уровня 2. Например, мост можно запрограммировать так, чтобы он
отвергал (т.е. не пропускал) все фреймы, посылаемые из
определенной сети. Т.к. в информацию канального уровня часто
включается ссылка на протокол высшего уровня, мосты обычно фильтруют
по этому параметру. Кроме того, мосты могут быть полезны, когда они
имеют дело с необязательной информацией пакетов широкой рассылки.
Разделяя крупные сети на автономные блоки, мосты обеспечивают
ряд преимуществ. Во-первых, поскольку пересылается лишь некоторый
процент трафика, мосты уменьшают трафик, проходящий через устройства
всех соединенных сегментов. Во-вторых, мосты действуют как
непреодолимая преграда для некоторых потенциально опасных для сети
неисправностей. В-третьих, мосты позволяют осуществлять связь между
большим числом устройств, чем ее можно было бы обеспечить на любой
LAN, подсоединенной к мосту, если бы она была независима.
В-четвертых, мосты увеличивают эффективную длину LAN, позволяя
подключать еще не подсоединенные отдаленные станции.
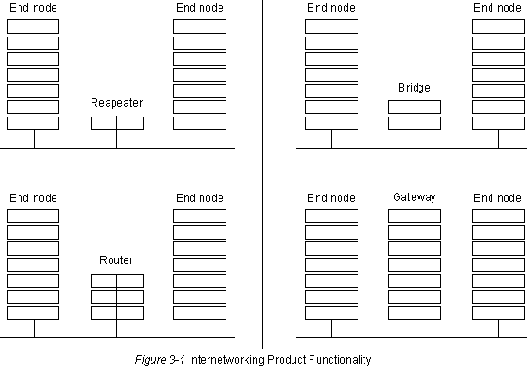
Сравнение устройств для объединения сетей
Устройства об'единения сетей обеспечивают связь между сегментами
локальных сетей (LAN). Существуют 4 основных типа устройств
об'единения сетей: повторители, мосты, роутеры и межсетевые
интерфейсы. Эти устройства в самом общем виде могут быть
дифференцированы тем уровнем "Межсоединений Открытых Систем" (OSI),
на котором они устанавливают соединение между LAN. Повторители
соединяют LAN на Уровне 1 OSI; мосты соединяют LAN на Уровне 2;
роутеры соединяют LAN на Уровне 3; межсетевые интерфейсы
соединяют LAN на Уровнях 4-7. Каждое устройство обеспечивает
функциональные возможности, соответствующие своему уровню, а
также использует функциональные возможности всех более низких
уровней. Эта положение иллюстрируется графически на Рис. 3-1.
Типы мостов
Мосты можно сгруппировать в категории, базирующиеся на различных
характеристиках изделий. В соответствии с одной из популярных схем
классификации мосты бывают локальные и дистанционные. Локальные мосты
обеспечивают прямое соединение множества сегментов LAN, находящихся
на одной территории. Дистанционные мосты соединяют множество
сегментов LAN на различных территориях, обычно через
телекоммуникационные линии. Эти две конфигурации представлены на
Рис. 3-2.

Дистанционное мостовое соединение представляет ряд уникальных
трудностей об'единения сетей. Одна из них - разница между скоростями
LAN и WAN (глобальная сеть). Хотя в последнее время в географически
рассредоточенных об'единенных сетях появилось несколько технологий
быстродействующих WAN, скорости LAN часто на порядок выше
скоростей WAN. Большая разница скоростей LAN и WAN иногда не
позволяет пользователям прогoнять через WAN применения LAN,
чуствительные к задержкам.
Дистанционные мосты не могут увеличить скорость WAN, однако они
могут компенсировать несоответствия в скоростях путем использования
достаточных буферных мощностей. Если какое-либо устройство LAN,
способной передавать со скоростью 3 Mb/сек, намерено связаться с
одним из устройств отдаленной LAN, то локальный мост должен
регулировать поток информации, передаваемой со скоростью 3Mb/сек,
чтобы не переполнить последовательный канал, который пропускает
64 Kb/сек. Это достигается путем накопления поступающей информации
в расположенных на плате буферах и посылки ее через последовательный
канал со скоростью, которую он может обеспечить. Это осуществимо
только для коротких пакетов информации, которые не переполняют
буферные мощности моста.
IEEE (Институт инженеров по электротехнике и радиоэлектронике)
поделил канальный уровень OSI на два отдельных подуровня: подуровень
MAC (Управление доступом к носителю) и подуровень LLC (Управление
логическим каналом). МАС разрешает и оркестрирует доступ к носителю
(Например, конфликтные ситуации, эстафетная передача и др.), в то
время как подуровень LLC занят кадрированием, управлением потоком
информации, управлением неисправностями и адресацией подуровня
МАС.
Некоторые мосты являются мостами подуровня МАС. Эти устройства
образуют мост между гомогенными сетями (например, IEEE 802.3 и
IEEE 802.3). Другие мосты могут осуществлять трансляцию между
различными протоколами канального уровня (например, IEEE 802.3 и
IEEE 802.5). Базовый механизм такой трансляции показан на Рис. 3-3.

На Рис. 3-3 главная вычислительная машина IEEE 802.3 (Главная
вычислительная машина А) формулирует пакет, содержащий прикладную
информацию, и герметизирует этот пакет в совместимый с IEEE 802.3
фрейм для передачи через среду IEEE 802.3 в мост. Внутри моста
фрейм освобождается от заголовка IEEE 802.3 в подуровне МАС
канального уровня и затем передается выше в подуровень LLC для
дальнейшей обработки. После обработки пакет снова передается
вниз в реализацию IEEE 802.5, которая герметизирует пакет в
заголовок IEEE 802.5 для передачи через сеть IEEE 802.5 в главную
вычислительную машину IEEE 802.5 (Главная вычислительная машина В).
Трансляция, осуществляемая мостом между различными типами сетей,
никогда не бывает безупречной, т.к. всегда имеется вероятность, что
одна сеть поддержит определенный фрейм, который не поддерживается
другой сетью. Эту ситуацию можно считать примерно аналогичной
проблеме, с которой сталкивается эскимос, пытающийся перевести на
английский некоторые слова из тех 50 слов, которые обозначают "снег".
Более подробно многие из вопросов трансляции через мосты обсуждаются
в Главе 31
.
[]
[]
[]
Архитектура управления сети
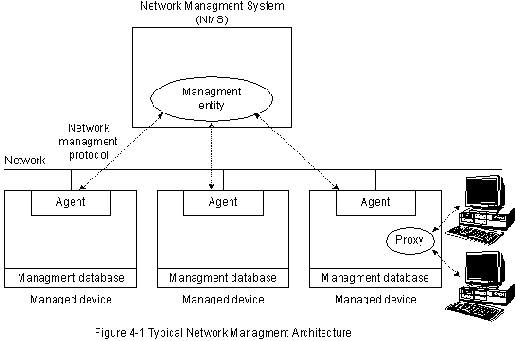
Большинство архитектур управления сети используют одну и ту же
базовую структуру и набор взаимоотношений. Конечные станции
(managed devices - управляемые устройства), такие как компьютерные
системы и другие сетевые устройства, прогoняют программные средства,
позволяющие им посылать сигналы тревоги, когда они распознают
проблемы. Проблемы распознаются, когда превышен один или более
порогов, заданных пользователем. Management entities (управляющие
об'екты) запрограммированы таким образом, что после получения
этих сигналов тревоги они реагируют выполнением одного, нескольких
или группы действий, включающих:
Уведомление оператора
Регистрацию события
Отключение системы
Автоматические попытки исправления системы
Управляющие об'екты могут также опросить конечные станции, чтобы
проверить некоторые переменные. Опрос может быть автоматическим или
его может инициировать пользователь. На эти запросы в управляемых
устройствах отвечают "агенты". Агенты - это программные модули,
которые накапливают информацию об управляемом устройстве, в котором
они расположены, хранят эту информацию в "базе данных управления" и
предоставляют ее (проактивно или реактивно) в управляющие об'екты,
находящиеся в пределах "систем управления сети" (NMSs), через
протокол управления сети. В число известных протоколов управления
сети входят "the Simple Network Management Protocol (SPMP)"
(Протокол Управления Простой Сети) и "Common Management Information
Protocol (CMIP)" (Протокол Информации Общего Управления).
"Management proxies" (Уполномоченные управления) - это об'екты,
которые обеспечивают информацию управления от имени других об'ектов.
Типичная архитектура управления сети показана на рис. 4-1.
Библиографическая справка
Начало 1980гг. ознаменовалось резким ростом в области применения
сетей. Как только компании поняли, что сетевая технология обеспечивает
им сокращение расходов и повышение производительности, они начали
устанавливать новые и расширять уже существующие сети почти с такой
же скоростью, с какой появлялись новые технологии сетей и изделия
для них. К середине 1980гг. стали очевидными проблемы, число которых
все более увеличивалось, связанные с этим ростом, особенно у тех
компаний, которые применили много разных (и несовместимых) технологий
сети.
Основными проблемами, связанными с увеличением сетей, являются
каждодневное управление работой сети и стратегическое планирование
роста сети. Характерным является то, что каждая новая технология
сети требует свою собственную группу экспертов для ее работы и
поддержки. В начале 1980гг. стратегическое планирование роста этих
сетей превратилось в какой-то кошмар. Одни только требования к числу
персонала для управления крупными гетерогенными сетями привели
многие организации на грань кризиса. Насущной необходимостью стало
автоматизированное управление сетями (включая то, что обычно
называется "планированием возможностей сети"), интегрированное по
всем различным окружениям.
В настоящей главе описываются технические характеристики, общие
для большинства архитектур и протоколов управления сетями. В ней
также представлены 5 функциональных областей управления ,
определенных Международной Оврганизацией по Стандартизации (ISO).
Модель управления сети ISO
ISO внесла большой вклад в стандартизацию сетей. Модель
управления сети этой организации является основным средством для
понимания главных функций систем управления сети. Эта модель состоит
из 5 концептуальных областей:
Управление эффективностью
Цель управления эффективностью - измерение и обеспечение
различных аспектов эффективности сети для того, чтобы
межсетевая эффективность могла поддерживаться на приемлемом
уровне. Примерами переменных эффективности, которые могли бы быть
обеспечены, являются пропускная способность сети, время реакции
пользователей и коэффициент использования линии.
Управление эффективностью включает несколько этапов:
Сбор информации об эффективности по тем переменным, которые
предствляют интерес для администраторов сети.
Анализ информации для определения нормальных (базовая
строка) уровней.
Определение соответствующих порогoв эффективности для каждой
важной переменной таким образом, что превышение этих порогов
указывает на наличие проблемы в сети, достойной внимания.
Управляемые об'екты постоянно контролируют переменные
эффективности. При превышении порога эффективности вырабатывается
и посылается в NMS сигнал тревоги.
Каждый из описанных выше этапов является частью процесса
установки реактивной системы. Если эффективность становится
неприемлемой вследствие превышения установленного пользователем
порога, система реагирует посылкой сообщения. Управление
эффективностью позволяет также использовать проактивные методы.
Например, при проектировании воздействия роста сети на показатели
ее эффективности может быть использован имитатор сети. Такие
имитаторы могут эффективно предупреждать администраторов о
надвигающихся проблемах для того, чтобы можно было принять
контрактивные меры.
Управление конфигурацией
Цель управления конфигурацией - контролирование информации о сете-
вой и системной конфигурации для того, чтобы можно было отслеживать и
управлять воздействием на работу сети различных версий аппаратных
и программных элементов. Т.к. все аппаратные и программные
элементы имеют эксплуатационные отклонения, погрешности, или то и
другое вместе, которые могут влиять на работу сети, такая информация
важна для поддержания гладкой работы сети.
Каждое устройство сети располагает разнообразной информацией о
версиях, ассоциируемых с ним. Например, АРМ проектировщика может
иметь следующую конфигурацию:
Операционная система, Version 3.2
Интерфейс Ethernet, Version 5.4
Программное обеспечение TCP/IP, Version 2.0
Программное обеспечение NetWare, Version 4.1
Программное обеспечение NFS, Version 5.1
Контроллер последовательных сообщений, Version 1.1
Программное обеспечение Х.25, Version 1.0
Прoграммное обеспечение SNMP, Version 3.1
Чтобы обеспечить легкий доступ, подсистемы управления
конфигурацией хранят эту информацию в базе данных. Когда возникает
какая-нибудь проблема, в этой базе данных может быть проведен поиск
ключей, которые могли бы помочь решить эту проблему.
Управление неисправностями
Цель управления неисправностями - выявить, зафиксировать,
уведомить пользователей и (в пределах возможного) автоматически
устранить проблемы в сети с тем, чтобы эффективно поддерживать
работу сети. Т.к. неисправности могут привести к простоям или
недопустимой деградации сети, управление несправностями, по всей
вероятности, является наиболее широко используемым элементом
модели управления сети ISO.
Управление неисправностями включает в себя несколько шагов:
Определение симптомов проблемы.
Изолирование проблемы.
Устранение проблемы.
Проверка устранения неисправности на всех важных подсистемах.
Регистрация обнаружения проблемы и ее решения.
Управление учетом использования ресурсов
Цель управления учетом использования ресурсов - измерение
параметров использования сети, чтобы можно было соответствующим
образом регулировать ее использование индивидуальными или
групповыми пользователями. Такое регулирование минимизирует число
проблем в сети (т.к. ресурсы сети могут быть поделены исходя из
возможностей источника) и максимизировать равнодоступность к сети
для всех пользователей.
Как и для случая управления эффективностью, первым шагом к
соответствующему управлению учетом использования ресурсов является
измерение коэффициента использования всех важных сетевых ресурсов.
Анализ результатов дает возможность понять текущую картину
использования. В этой точке могут быть установлены доли пользования.
Для достижения оптимальной практики получения доступа может
потребоваться определенная коррекция. Начиная с этого момента,
последующие измерения использования ресурсов могут выдавать
информацию о выставленных счетах, наряду с информацией,
использованной для оценки наличия равнодоступности и оптимального
каоэффициента использования источника.
Управление защитой данных
Цель управления защитой данных - контроль доступа к сетевым
ресурсам в соответствии с местными руководящими принципами,
чтобы сделать невозможными саботаж сети и доступ к чувствительной
информации лицам, не имеющим соответствующего разрешения.
Например, одна из подсистем управления защитой данных может
контролировать регистрацию пользователей ресурса сети, отказывая в
доступе тем, кто вводит коды доступа, не соответствующие
установленным.
Подсистемы управления защитой данных работают путем разделения
источников на санкционированные и несанкционированные области. Для
некоторых пользователей доступ к любому источнику сети является
несоответствующим. Такими пользователями, как правило, являются не
члены компании. Для других пользователей сети (внутренних)
несоответствующим является доступ к информации, исходящей из какого-
либо отдельного отдела. Например, доступ к файлам о людских
ресурсах является несоответствующим для любых пользователей, не
принадлежащих к отделу управления людскими ресурсами (исключением
может быть администраторский персонал).
Подсистемы управления защитой данных выполняют следующие функции:
Идентифицируют чувствительные ресурсы сети (включая системы,
файлы и другие об'екты)
Определяют отображения в виде карт между чувствительными
источниками сети и набором пользователей
Контролируют точки доступа к чувствительным ресурсам сети
Регистрируют несоответствующий доступ к чувствительным
ресурсам сети.
[]
[]
[]
Физическое подключение
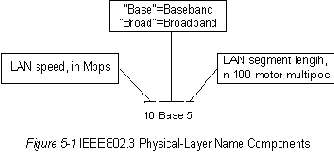
IEEE 802.3 specifies several different physical layers, whereas Ethernet defines only one. Each IEEE 802.3 physical layer protocol has a name that summarizes its characteristics. The coded components of an IEEE 802.3 physical-layer name are shown in Figure
5-1.
Figure 5-1 : IEEE 802.3 Physical-Layer Name Components
A summary of Ethernet Version 2 and IEEE 802.3 characteristics appears in Table 5-1.
| Скорость, Mbps | 10 | 10 | 10 | 1 | 10 | 10 |
| Метод передачи | Baseband | Baseband | Baseband | Baseband | Baseband | Broadband |
| Макс. длина сегмента, м | 500 | 500 | 185 | 250 | 100 | 1800 |
| Среда передачи | 50-Ом коаксиал (толстый) | 50-Ом коаксиал (толстый) | 50-Ом коаксиал (тонкий) | неэкр. витая пара | неэкр. витая пара | 75-ohm coax |
| Топология | Шина | Шина | Шина | Звезда | Звезда | Шина |
Table 5-1 Ethernet Version 2 and IEEE 802.3 Physical Characteristics
Ethernet is most similar to IEEE 802.3 10Base5. Both of these protocols specify a bus topology network with a connecting cable between the end stations and the actual network medium. In the case of Ethernet, that cable is called a transceiver cable. The transceiver cable connects to a transceiver device attached to the physical network medium. The IEEE 802.3 configuration is much the same, except that the connecting cable is referred to as an attachment unit interface (AUI), and the transceiver is called a medium attachment unit (MAU). In both cases, the connecting cable attaches to an interface board (or interface circuitry) within the end station.
Форматы блоков
Ethernet and IEEE 802.3 frame formats are shown in Figure 5-2.

Both Ethernet and IEEE 802.3 frames begin with an alternating pattern of ones and zeros called a preamble. The preamble tells receiving stations that a frame is coming.
The byte before the destination address in both an Ethernet and a IEEE 802.3 frame is a start-of-frame (SOF) delimiter. This byte ends with two consecutive one bits, which serve to synchronize the frame reception portions of all stations on the LAN.
Immediately following the preamble in both Ethernet and IEEE 802.3 LANs are the destination and source address fields. Both Ethernet and IEEE 802.3 addresses are 6 bytes long. Addresses are contained in hardware on the Ethernet and IEEE 802.3 interface cards. The first 3 bytes of the addresses are specified by the IEEE on a vendor-dependent basis, while the last 3 bytes are specified by the Ethernet or IEEE 802.3 vendor. The source address is always a unicast (single node) address, while the destination address may be unicast, multicast (group), or broadcast (all nodes).
In Ethernet frames, the 2-byte field following the source address is a type field. This field specifies the upper-layer protocol to receive the data after Ethernet processing is complete.
In IEEE 802.3 frames, the 2-byte field following the source address is a length field, which indicates the number of bytes of data that follow this field and precede the frame check sequence (FCS) field.
Following the type/length field is the actual data contained in the frame. After physical-layer and link-layer processing is complete, this data will eventually be sent to an upper-layer protocol. In the case of Ethernet, the upper-layer protocol is identified in the type field. In the case of IEEE 802.3, the upper-layer protocol must be defined within the data portion of the frame, if at all. If data in the frame is insufficient to fill the frame to its minimum 64-byte size, padding bytes are inserted to ensure at least a 64-byte frame.
After the data field is a 4-byte FCS field containing a cyclic redundancy check (CRC) value. The CRC is created by the sending device and recalculated by the receiving device to check for damage that might have occurred to the frame in transit.
[]
[]
[]
Основы технологии
Ethernet был разработан Исследовательским центром в Пало Альто (PARC) корпорации Xerox в 1970-м году. Ethernet стал основой для спецификации IEEE 802.3, которая появилась 1980-м году. После недолгих споров компании Digital Equipment Corporation, Intel Corporation и Xerox Corporation совместно разработали и приняли спецификацию (Version 2.0), которая была частично совместима с 802.3. На сегодняшний день Ethernet и IEEE 802.3 являются наиболее распространенными протоколами локальных вычислительных сетей (ЛВС). Сегодня термин Ethernet чаще всего используется для описания всех ЛВС работающих по принципу множественный доступ с обнаружением несущей (carrier sense multiple access/collision detection (CSMA/CD)), которые соотвествуют Ethernet, включая IEEE 802.3.
Когда Ethernet был разработан, он должен был заполнить нишу между глобальными сетями, низкоскоростными сетями и специализированными сетями компьтерных центров, которые работали на высокой скрости, но очень органиченном расстоянии. Ethernet хорошо подходит для приложений где локальные коммуникации должны выдерживать высокие нагрузки при высоких скоростях в пиках.
specify similar technologies. Both
Ethernet and IEEE 802. 3 specify similar technologies. Both are CSMA/CD LANs. Stations on a CSMA/CD LAN can access the network at any time. Before sending data, CSMA/CD stations "listen" to the network to see if it is already in use. If it is, the station wishing to transmit waits. If the network is not in use, the station transmits. A collision occurs when two stations listen for network traffic, "hear" none, and transmit simultaneously. In this case, both transmissions are damaged, and the stations must retransmit at some later time. Backoff algorithms determine when the colliding stations retransmit. CSMA/CD stations can detect collisions, so they know when they must retransmit.
Both Ethernet and IEEE 802.3 LANs are broadcast networks. In other words, all stations see all frames, regardless of whether they represent an intended destination. Each station must examine received frames to determine if the station is a destination. If so, the frame is passed to a higher protocol layer for appropriate processing.
Differences between Ethernet and IEEE 802.3 LANs are subtle. Ethernet provides services corresponding to Layers 1 and 2 of the OSI reference model, while IEEE 802.3 specifies the physical layer (Layer 1) and the channel-access portion of the link layer (Layer 2), but does not define a logical link control protocol. Both Ethernet and IEEE 802.3 are implemented in hardware. Typically, the physical manifestation of these protocols is either an interface card in a host computer or circuitry on a primary circuit board within a host computer.
Библиографическая справка
Сеть Token Ring первоначально была разработана компанией IBM в
1970 гг. Она попрежнему является основной технологией IBM для
локальных сетей (LAN) , уступая по популярности среди технологий LAN
только Ethernet/IEEE 802.3. Спецификация IEEE 802.5 почти идентична
и полностью совместима с сетью Token Ring IBM. Спецификация
IEEE 802.5 была фактически создана по образцу Token Ring IBM, и она
продолжает отслеживать ее разработку. Термин "Token Ring" oбычно
применяется как при ссылке на сеть Token Ring IBM, так и на
сеть IEEE 802.5.
Физические соединения
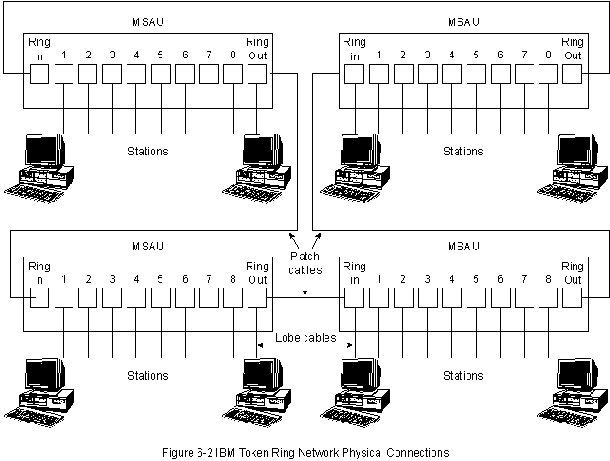
Станции сети IBM Token Ring напрямую подключаются к
MSAU, которые могут быть об'единены с помощью кабелей,
образуя одну большую кольцевую сеть (смотри Рис. 6-2). Кабели-
перемычки соединяют MSAU со смежными MSAU. Кабели-лепестки
подключают MSAU к станциям. В составе МSAU имеются шунтирующие
реле для исключения станций из кольца.
Формат блока данных
Сети Token Ring определяют два типа блока данных: блоки маркеров и
блоки данных/блоки команд. Оба формата представлены на Рис.6-3.

Маркеры
Длина маркера - три байта; он состоит из
ограничителя начала
Ограничитель начала служит для предупреждения каждой
станции о прибытии маркера (или блока данных/блока команд).
В этом поле имеются сигналы, которые отличают этот байт от
остальной части блока путем нарушения схемы кодирования,
использованной в других частях блока.
байта управления доступом
Байт управления доступом содержит поля приоритета и
резервирования, а также бит маркера (используемый для
дифференциации маркера и блока данных/блока команд) и
бит монитора (используемый активным монитором, чтобы
определить, циркулирует какой-либо блок в кольце непрерывно
или нет).
ограничителя конца
И наконец, разделитель конца сигнализирует о конце маркера
или блока данных/ блока команд. В нем также имеются биты для
индикации поврежденного блока,а также блока, являющегося
последним в логической последовательности.
Блок данных и блок команд
Блок данных и блок команд могут иметь разные размеры в зависимости
от размеров информационного поля. Блоки данных переносят
информацию для протоколов высших уровней; блоки команд содержат
управляющую информацию, в них отсутствует информация для протоколов
высших уровней.
В блоке данных/ блоке команд за байтом управления доступом следует
байт управления блоком данных. Байт управления блоком данных указывает,
что содержит блок - данные или управляющую информацию. В управляющих
блоках этот байт определяет тип управляющей информации.
За байтом управления блоком следуют два адресных поля, которые
идентифицируют станции пункта назначения и источника. Для IEEE 802.5
длина адресов равна 6 байтам.
За адресными полями идет поле данных. Длина этого поля ограничена
временем удержания маркера кольца, которое определяет максимальное
время, в течение которого станция может удерживать маркер.
За полем данных идет поле последовательности проверки блока (FCS).
Станция-источник заполняет это поле вычисленной величиной,
зависящей от содержания блока данных. Станция назначения повторно
вычисляет эту величину, чтобы определить, не был ли блок поврежден
при прохождении. Если это так, то блок отбрасывается.
Также, как и маркер, блок данных/ блок команд заканчивается
ограничителем конца.
[]
[]
[]
Механизмы управления неисправостями
Сети Token Ring используют несколько механизмов обнаружения и
компенсации неисправностей в сети. Например, одна станция в сети
Token Ring выбирается "активным монитором" (active monitor). Эта
станция, которой в принципе может быть любая станция сети,
действует как централизованный источник синхронизирующей информации
для других станций кольца и выполняет разнообразразные функции для
поддержания кольца. Одной из таких функций является удаление из
кольца постоянно циркулирующих блоков данных. Если устройство,
отправившее блок данных, отказало, то этот блок может постоянно
циркулировать по кольцу. Это может помешать другим станциям передавать
собственные блоки данных и фактически блокирует сеть. Активный монитор
может выявлять и удалять такие блоки и генерировать новый маркер.
Звездообразная топология сети IBM Token Ring также способствует
повышению общей надежности сети. Т.к. вся информация сети Token
Ring просматривется активными MSAU, эти устройства можно
запрограммировать так, чтобы они проверяли наличие проблем и
при необходимости выборочно удаляли станции из кольца.
Алгоритм Token Ring, называемый "сигнализирующим" (beaconing),
выявляет и пытается устранить некоторые неисправности сети. Если
какая-нибудь станция обнаружит серьезную проблему в сети (например
такую, как обрыв кабеля), она высылает сигнальный блок данных.
Сигнальный блок данных указывает домен неисправности, в который входят
станция, сообщающая о неисправности, ее ближайший активный сосед,
находящийся выше по течению потока информации (NAUN), и все, что
находится между ними. Сигнализация инициализирует процесс, называемый
"автореконфигурацией" (autoreconfiguration), в ходе которого
узлы, расположенные в пределах отказавшего домена, автоматически
выполняют диагностику, пытаясь реконфигурировать сеть вокруг
отказавшей зоны. В физическом плане MSAU может выполнить это с
помощью электрической реконфигурации.
Передача маркера
Token Ring и IEEE 802.5 являются главными примерами сетей с
передачей маркера. Сети с передачей маркера перемещают вдоль сети
небольшой блок данных, называемый маркером. Владение этим маркером
гарантирует право передачи. Если узел, принимающий маркер, не имеет
информации для отправки, он просто переправляет маркер к следующей
конечной станции. Каждая станция может удерживать маркер в течение
определенного максимального времени.
Если у станции, владеющей маркером, имеется информации для
передачи, она захватывает маркер, изменяет у него один бит (в
результате чего маркер превращается в последовательность "начало
блока данных"), дополняет информацией, которую он хочет передать
и, наконец, отсылает эту информацию к следующей станции кольцевой
сети. Когда информационный блок циркулирует по кольцу, маркер в
сети отсутствует (если только кольцо не обеспечивает "раннего
освобождения маркера" - early token release), поэтому другие
станции, желающие передать информацию, вынуждены ожидать.
Следовательно, в сетях Token Ring не может быть коллизий. Если
обеспечивается раннее высвобождение маркера, то новый маркер может
быть выпущен после завершения передачи блока данных.
Информационный блок циркулирует по кольцу, пока не достигнет
предполагаемой станции назначения, которая копирует информацию
для дальнейшей обработки. Информационный блок продолжает
циркулировать по кольцу; он окончательно удаляется после достижения
станции, отославшей этот блок. Станция отправки может проверить
вернувшийся блок, чтобы убедиться, что он был просмотрен и затем
скопирован станцией назначения.
В отличие от сетей CSMA/CD (например, Ethernet) сети с передачей
маркера являются детерминистическими сетями. Это означает, что
можно вычислить максимальное время, которое пройдет,прежде чем
любая конечная станция сможет передавать. Эта характеристика, а
также некоторые характеристики надежности, которые будут рассмотрены
дальше, делают сеть Token Ring идеальной для применений, где задержка
должна быть предсказуема и важна устойчивость функционирования
сети. Примерами таких применений является среда автоматизированных
станций на заводах.
Система приоритетов
Сети Тоkеn Ring используют сложную систему приоритетов,
которая позволяет некоторым станциям с высоким приоритетом,
назначенным пользователем, более часто пользоваться сетью. Блоки
данных Token Ring содержат два поля, которые управляют приоритетом:
поле приоритетов и поле резервирования.
Только станции с приоритетом, который равен или выше величины
приоритета, содержащейся в маркере, могут завладеть им. После того,
как маркер захвачен и изменен( в результате чего он превратился в
информационный блок), только станции, приоритет которых выше
приоритета передающей станции, могут зарезервировать маркер для
следующего прохода по сети. При генерации следующего маркера в
него включается более высокий приоритет данной резервирующей
станции. Станции, которые повышают уровень приоритета маркера,
должны восстановить предыдущий уровень приоритета после завершения
передачи.
их спецификации имеют относительно небольшие
Сети Token Ring и IEEE 802.5 в основном почти совместимы, хотя
их спецификации имеют относительно небольшие различия.
Сеть Token Ring IBM оговаривает звездообразное соединение,
причем все конечные устройства подключаются к устройству, называемому
"устройством доступа к многостанционной сети" (MSAU), в то время
как IEEE 802.5 не оговаривает топологию сети (хотя виртуально все
реализации IEEE 802.5 также базируются на звездообразной сети).
Имеются и другие отличия, в том числе тип носителя (IEEE 802.5 не
оговаривает тип носителя, в то время как сети Toke Ring IBM
используют витую пару) и размер поля маршрутной информации
(смотри далее в этой главе обсуждение характеристик полей
маршрутной информации). На Рис. 6-1 представлены обобщенные
характеристики сетей Token Ring и IЕЕЕ 802.5.
| IBM Token Ring NetworkIEEE 802.5 | |
| 4.16 Mbps | 4.16 Mbps |
| 260 (S.T.P.) 72 (U.T.P.) | 250 |
| Star | Not specified |
| Twisted pair | Not specified |
| Baseband | Baseband |
| Token passing | Token passing |
| Differential Manchester | Differential Manchester |
Библиографическая справка
Стандарт на "Волоконно-оптический интерфейс по распределенным данным"
(FDDI) был выпущен ANSI X3Т9.5 (комитет по разработке стандартов)
в середине 1980 гг. В этот период быстродействующие АРМ проектировщика
уже начинали требовать максимального напряжения возможностей
существующих локальных сетей (LAN) (в oсновном Ethernet и Token
Ring). Возникла необходимость в новой LAN, которая могла бы легко
поддерживать эти АРМ и их новые прикладные распределенные системы.
Одновременно все большее значение уделяется проблеме надежности сети,
т.к. администраторы систем начали переносить критические по
назначению прикладные задачи из больших компьютеров в сети. FDDI
была создана для того, чтобы удовлетворить эти потребности.
После завершения работы над FDDI, ANSI представила его на рассмотрение
в ISO. ISO разработала международный вариант FDDI, который полностью
совместим с вариантом стандарта, разработанным ANSI.
Хотя реализации FDDI сегодня не столь распространены, как Ethernet
или Token Ring, FDDI приобрела значительное число своих
последователей, которое увеличивается по мере уменьшения стоимости
интерфейса FDDI. FDDI часто используется как основа
технологий, а также как средство для соединения быстродействующих
компьютеров, находящихся в локальной области.
Физические соединения
FDDI устанавливает применение двойных кольцевых сетей. Трафик по
этим кольцам движется в противоположных направлениях. В физическом
выражении кольцо состоит из двух или более двухточечных соединений
между смежными станциями. Одно из двух колец FDDI называется
первичным кольцом, другое-вторичным кольцом. Первичное кольцо
используется для передачи данных, в то время как вторичное кольцо
обычно является дублирующим.
"Станции Класса В" или "станции, подключаемые к одному кольцу" (SAS)
подсоединены к одной кольцевой сети; "станции класса А" или "станции,
подключаемые к двум кольцам" (DAS) подсоединены к обеим кольцевым
сетям. SAS подключены к первичному кольцу через "концентратор",
который обеспечивает связи для множества SAS. Koнцентратор отвечает
за то, чтобы отказ или отключение питания в любой из SAS не прерывали
кольцо. Это особенно необходимо, когда к кольцу подключен РС или
аналогичные устройства, у которых питание часто включается и
выключается.
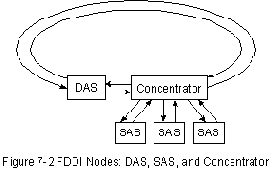
На Рис. 7-2 "Узлы FDDI: DAS, SAS и концентратор" представлена
типичная конфигурация FDDI, включающая как DAS, так и SAS.
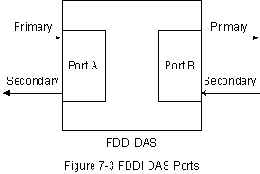
Каждая DAS FDDI имеет два порта, обозначенных А и В. Эти порты
подключают станцию к двойному кольцу FDDI. Следовательно, как это
показано на Рис. 7-3 "Порты DAS FDDI", каждый порт обеспечивает
соединение как с первичным, так и со вторичным кольцом.
Формат блока данных
Форматы блока данных FDDI (представлены на Рис. 7-7) аналогичны
форматам Token Ring.
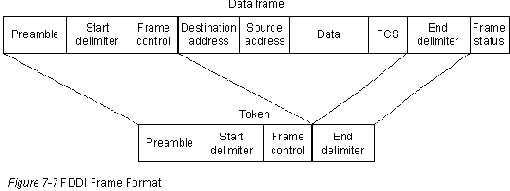
preamble
Заголовок подготавливает каждую станцию для приема прибывающего
блока данных.
start delimiter
Ограничитель начала указывает на начало блока данных. Он содержит
сигнальные структуры, которые отличают его от остальной части
блока данных.
frame control
Поле управления блоком данных указывает на размер адресных полей,
на вид данных, содержащихся в блоке (синхронная или асинхронная
информация), и на другую управляющую информацию.
destination address
Также, как у Ethernet и Token Ring, размер адресов равен 6 байтам.
Поле адреса назначения может содержать односоставный (единственный),
многосоставный (групповой) или широковещательный (все станции)
адрес, в то время как адрес источника идентифицирует только одну
станцию, отправившую блок данных.
data
Информационное поле содержит либо информацию, предназначенную
для протокола высшего уровня, либо управляющую информацию.
frame check sequence
Также, как у Token Ring и Ethernet, поле проверочной
последовательности блока данных (FCS) заполняется величиной
"проверки избыточности цикла" (CRC), зависящей от содержания блока
данных, которую вычисляет станция- источник. Станция пункта назначения
пересчитывает эту величину, чтобы определить наличие возможного
повреждения блока данных при транзите. Если повреждение имеется, то
блок данных отбрасывается.
end delimiter
Ограничитель конца содержит неинформационные символы, которые
означают конец блока данных.
frame status
Поле состояния блока данных позволяет станции источника определять,
не появилась ли ошибка, и был ли блок данных признан и скопирован
принимающей станцией.
[]
[]
[]
Основы технологии
Стандарт FDDI определяет 100 Mb/сек. LAN с двойным кольцом и
передачей маркера, которая использует в качестве среды передачи
волоконно-оптический кабель. Он определяет физический уровень и
часть канального уровня, которая отвечает за доступ к носителю;
поэтому его взаимоотношения с эталонной моделью OSI примерно
аналогичны тем, которые характеризуют IEEE 802.3 и IЕЕЕ 802.5.
Хотя она работает на более высоких скоростях, FDDI во многом
похожа на Token Ring. Oбe сети имеют одинаковые характеристики,
включая топологию (кольцевая сеть), технику доступа к носителю
(передача маркера), характеристики надежности (например,
сигнализация-beaconing), и др. За дополнительной информацией по
Token Ring и связанными с ней технологиями обращайтесь к Главе 6
.
Одной из наиболее важных характеристик FDDI является то, что она
использует световод в качестве передающей среды. Световод
обеспечивает ряд преимуществ по сравнению с традиционной медной
проводкой, включая защиту данных (оптоволокно не излучает
электрические сигналы, которые можно перехватывать), надежность
(оптоволокно устойчиво к электрическим помехам) и скорость
(потенциальная пропускная способность световода намного выше, чем
у медного кабеля).
FDDI устанавливает два типа используемoгo оптического волокна:
одномодовое (иногда называемое мономодовым) и многомодовое.
Моды можно представить в виде пучков лучей света, входящего в
оптическое волокно под определенным углом. Одномодовое волокно
позволяет распространяться через оптическое волокно только одному
моду света, в то время как многомодовое волокно позволяет
распространяться по оптическому волокну множеству мод света.
Т.к. множество мод света, распространяющихся по оптическому кабелю,
могут проходить различные расстояния (в зависимости от угла входа),
и, следовательно, достигать пункт назначения в разное время
(явление, называемое модальной дисперсией), одномодовый световод
способен обеспечивать большую полосу пропускания и прогoн кабеля на
большие расстояния, чем многомодовые световоды. Благодаря этим
характеристикам одномодовые световоды часто используются в качестве
основы университетских сетей, в то время как многомодовый световод
часто используется для соединения рабочих групп. В многомодовом
световоде в качестве генераторов света используются диоды,
излучающие свет (LED), в то время как в одномодовом световоде обычно
применяются лазеры.
Особенности отказоустойчивости
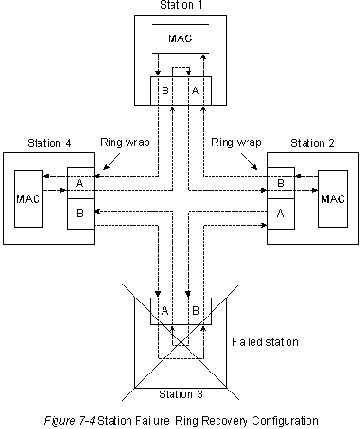
FDDI характеризуется рядом особенностей отказоустойчивости. Основной
особенностью отказоустойчивости является наличие двойной кольцевой
сети. Если какая-нибудь станция, подключенная к двойной кольцевой
сети, отказывает, или у нее отключается питание, или если поврежден
кабель, то двойная кольцевая сеть автоматически "свертывается"
("подгибается" внутрь) в одно кольцо, как показано на Рис.7-4
"Конфигурация восстановления кольца при отказе станции". При отказе
Станции 3, изображенной на рисунке, двойное кольцо автоматически
свертывается в Станциях 2 и 4, образуя одинарное кольцо. Хотя
Станция 3 больше не подключена к кольцу, сеть продолжает работать
для оставшихся станций.
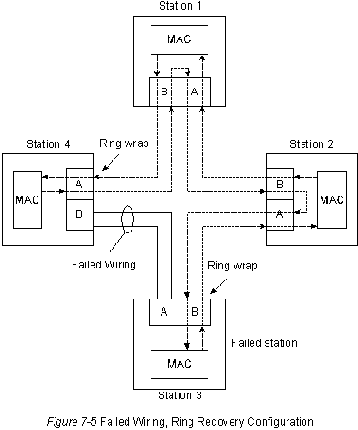
На Рис. 7-5 "Конфигурация восстановления сети при отказе кабеля"
показано, как FDDI компенсирует отказ в проводке. Станции 3 и 4
свертывают кольцо внутрь себя при отказе проводки между этими
станциями.
По мере увеличения размеров сетей FDDI растет вероятность увеличения
числа отказов кольцевой сети. Если имеют место два отказа кольцевой
сети, то кольцо будет свернуто в обоих случаях, что приводит к
фактическому сегментированию кольца на два отдельных кольца, которые
не могут сообщаться друг с другом. Последующие отказы вызовут
дополнительную сегментацию кольца.
Для предотвращения сегментации кольца могут быть использованы
оптические шунтирующие переключатели, которые исключают отказавшие
станции из кольца. На Рис. 7-6 показано "Использование оптического
шунтирующего переключателя".

Устройства, критичные к отказам, такие как роутеры или
главные универсальные вычислительные машины, могут использовать
другую технику повышения отказоустойчивости, называемую "двойным
подключением" (dual homing), для того, чтобы обеспечить
дополнительную
избыточность и повысить гарантию работоспособности. При двойном
подключении критичное к отказам устройство подсоединяется к двум
концентраторам. Одна пара каналов концентраторов считается активным
каналом; другую пару называют пассивным каналом. Пассивный канал
находится в режиме поддержки до тех пор, пока не будет установлено,
что основной канал (или концентратор, к которому он подключен)
отказал. Если это происходит,то пассивный канал автоматически
активируется.
Технические условия FDDI
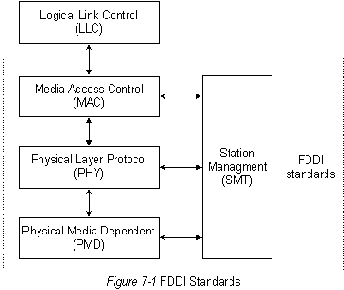
FDDI определяется 4-мя независимыми техническими условиями
(смотри Рис. 7-1 "Стандарты FDDI"):
Media Access Control (MAC) (Управление доступом к носителю)
определяет способ доступа к носителю, включая формат пакета,
обработку маркера, адресацию, алгоритм CRC (проверка избыточности
цикла) и механизмы устранения ошибок.
Physical Layer Protocol (PHY) (Протокол физического уровня)
определяет процедуры кодирования/декодирования информации,
требования к синхронизации, формированию кадров и другие функции.
Station Management (SMT) (Управление станциями)
определяет конфигурацию станций FDDI, конфигурацию кольцевой сети и
особенности управления кольцевой сетью, включая вставку и
исключение станций, инициализацию, изоляцию и устранение
неисправностей, составление графика и набор статистики.
Типы трафика
FDDI поддерживает распределение полосы пропускания сети в масштабе
реального времени, что является идеальным для ряда различных типов
прикладных задач. FDDI обеспечивает эту поддержку путем обозначения
двух типов трафика: синхронного и асинхронного. Синхронный трафик
может потреблять часть общей полосы пропускания сети FDDI, равную
100 Mb/сек; остальную часть может потреблять асинхронный трафик.
Синхронная полоса пропускания выделяется тем станциям, которым
необходима постоянная возможность передачи. Например, наличие такой
возможности помогает при передаче голоса и видеоинформации. Другие
станции используют остальную часть полосы пропускания асинхронно.
Спецификация SMT для сети FDDI определяет схему распределенных
заявок на выделение полосы пропускания FDDI.
Распределение асинхронной полосы пропускания производится с
использованием восьмиуровневой схемы приоритетов. Каждой станции
присваивается определенный уровень приоритета пользования
асинхронной полосой пропускания. FDDI также разрешает длительные
диалоги, когда станции могут временно использовать всю асинхронную
полосу пропускания. Механизм приоритетов FDDI может фактически
блокировать станции, которые не могут пользоваться синхронной полосой
пропускания и имеют слишком низкий приоритет пользования
асинхронной полосой пропускания.
Адаптеры каналов связи
Адаптеры каналов связи соединяют и передают информацию между двумя
концентраторами UltraNet или между концентратором UltraNet и
роутерами Cisco Systems AGS+. Имея в своем составе контроллеры
каналов связи, от одного до четырех мультиплексоров каналов связи
и одну плату пульта ручного управления для каждого мультиплексора
каналов связи, адаптеры каналов связи располагают полностью
дублированной частной шиной, мощность полосы пропускания которой
равна 1 Гигабит/сек.
На основе регурярно действующего принципа адаптеры каналов связи
определяют те адаптеры и концентраторы, к которым они непосредственно
подключаются. Адаптеры каналов связи рассылают ту или иную
маршрутную информацию в другие адаптеры каналов, чтобы осуществлять
динамичное построение и поддержание базы данных маршрутизации,
содержащей информацию о наилучшем маршруте до всех главных
вычислительных машин в пределах сети.
[]
[]
[]
Библиографическая справка
Система сети UltraNet, или просто UltraNet, состоит из семейства
высокоскоростных программ для об'единенных сетей
и аппаратных изделий, способных обеспечить совокупную пропускную
способность в один гигабайт в секунду (Gb/сек). UltraNet производится
и реализуется на рынке компанией Ultra Network Technologies.
UltraNet oбычно используется для соединения высокоскоростных
компьютерных систем, таких как суперкомпьютеры, минисуперкомпьютеры,
универсальные вычислительные машины, устройства обслуживания и АРМ.
UltraNet может быть сама соединена с другой сетью (например, Ethernet
и Token Ring) через роутеры, которые выполняют функции
межсетевого интерфейса.
Компоненты UltraNet
Сеть UltraNet состоит из различных компонентов, в том числе
концентраторов, программного обеспечения для главных вычислительных
машин, управляющих сети, сетеых процессоров и канальных адаптеров.
Описание этих системных элементов дается в следующих разделах.
Концентратор (hub) UltraNet
Концентратор в UltraNet является центральной точкой связи для
главных вычислительных машин сети UltraNet. Он содержит высоко-
скоростную внутреннюю параллельную шину (UltraBus), об'единяющую
все процессоры в пределах этого концентратора. UltraBus отвечает
за коммутируемую информацию в сети UltraNet. Концентраторы UltraNet
обеспечивают быстрое согласование, управление перегрузкой каналов
связи и прямое подключение каналов.
Основы технологии
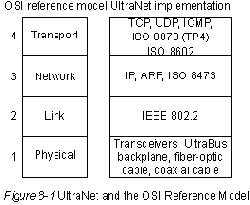
UltraNet обеспечивает услуги, соответствующие четырем низшим уровням
эталонной модели OSI. На Рис. 8-1 показаны взаимоотношения между этими
уровнями и реализацией UltraNet. В дополнение к перечисленным протоколам
UltraNet также обеспечивает Simple Network Management Protocol (SNMP)
(Протокол Управления Простой Сетью) и Routing Information Protocol
(RIP) (Протокол маршрутной информации). Дополнительная информация
по этим протоколам дается соответственно в Главе 23
и Главе 32 .
UltraNet использует топологию звездообразной сети с концентратором
сети (Hub) в центральной точке звезды. Другими компонентами системы
UltraNet являются программное обеспечение для главной вычислительной
машины, сетевые процессоры, канальные адаптеры, инструментальные
средства управления сети и изделия для об'единения сетей, такие как
роутеры и мосты. Сетевые процессоры соединяют главные
вычислительные машины с системой UltraNet и обеспечивают виртуальную
цепь и услуги дейтаграмм. Главные вычислительные машины,
непосредственно подключенные к системе UltraNet, могут быть
удалены друг от друга на расстояние до 30 км. Этот предел может
быть расширен подключением к глобальной сети (WAN), например, путем
использования каналов связи Т3.
Программное обеспечение главной вычислительной машины UltraNet
Программное обеспечение главной вычислительной машины UltraNet
состоит из:
Библиотек программирования, позволяющих пропускать через UltraNet
программы клиентов Transmission Control Protocol/Internet
Protocol (TCP/IP) (Протокол управления передачей/ Протокол
Internet) и графические прикладные программы.
Драйверов устройств сетевых процессоров, которые обеспечивают
интерфейс между процессами пользователя и сетевым процессором
UltraNet через адаптер процессора.
Поддержки системы программных гнезд, базирующейся на библиотеках
программ, UNIX Berkeley Standard Distribution (BSD).
Эта поддержка обеспечивается в форме совокупности библиотечных
функций языка С, которая заменяет стандартные обращения к системе
программных гнезд, чтобы обеспечить совместимость с существующими
прикладными задачами, базирующимися на программных гнездах.
Обслуживающие конфигурационные программы, которые дают возможность
пользователю определять сетевые процессоры, имеющиеся в
системе UltraNet, маршруты между концентраторами UltraNet и сетевыми
процессорами, а также адреса UltraNet.
Диагностические обслуживающие программы, которые позволяют
пользователям проверять систему UltraNet для обнаружения
возможных проблем. Эти обслуживающие программы могут запускаться
компьютером Ultra Network Manager (Управляющий сети UltraNet), а
также главной вычислительной машиной.
Сетевые процессоры
Сетеые процессоры UltraNet обеспечивают связи между концентраторами
UltraNet и главными вычислительными машинами. Имеются сетевые
процессоры, которые поддерживают каналы High-Perfomance Parallel
Interface (HIPPI) (Высокопроизводительный параллельный интерфейс),
HSX (обеспечивается Cray), ВМС (обеспечивается IBM) и LSC
(обеспечивается Cray), а также шины VMEbus, SBus, HP/EISA bus и
IBM Micro Channel bus. Сетевые процессоры могут находиться либо в
главной вычислительной машине, либо в концентраторе UltraNet.
Сетевой процессор, размещаемый в концентраторе, состоит из платы
процессора обработки протоколов, платы персонального модуля и
платы пульта ручного управления. Плата процессора обработки
протоколов выполняет команды сетевых протоколов; на ней имеются
буферы FIFO для выполнения буферизации пакетов и согласования
скоростей. Плата персонального модуля управляет обменом информации
между процессором обработки протоколов и различными средами сети,
каналами главной управляющей машины или специализированной аппаратурой.
Плата пульта ручного управления управляет устройством ввода/вывода
(I/O) информации между сетевым процессором и главной вычислительной
машиной, монитором графического дисплея или другим концентратором.
UltraNet также обеспечивает систему графического изображения с
высокой разрешающей способностью, которая принимает информацию
в пикселях из главной вычислительной машины UltraNet и отображает
ее на мониторе, подключенном к адаптеру. Это устройство называется
сетевым процессором кадрового буфера.
Большинство задач обработки сетевых протоколов выполняются сетевыми
процессорами UltraNet. Сетевые процессоры могут принимать реализации
TCP/IP и связанных с ним протоколов, а также модифицированные пакеты
протоколов OSI, чтобы осуществлять связь между главными
вычислительными машинами.
Управляющий сети UltraNet
Управляющий сети UltraNet обеспечивает инструментальные средства,
которые помогают инициализировать и управлять UltraNet. Физическим
выражением управляющего является базирующийся на Intel 80386 РС,
работающий в операционных системах DOS и Windows, который подключает
к концентратору UltraNet через шину управления сети (NMB). NMB
представляет собой независимую 1 Mg/сек LAN, базирующуюся на
спецификации StarLAN (1Base5). Управляющий UltraNet заменяет
информацию управления, пользуясь протоколом SNMP.
Библиографическая справка
Бесспорной тенденцией развития сетей является увеличение скорости
связи. В последнее время с появлением интерфейса Fiber Distributed Data
Interface (FDDI) (Волоконно-оптический интерфейс по распределенным
данным) локальные сети переместились в диапазон скоростей до
100 Mb/сек. Прикладные программы для локальных сетей, стимулирующие
это увеличение скоростей, включают передачу изображений, видеосигналов
и современные прикладные задачи передачи распределенной информации
(клиент-устройство обслуживания). Более быстродействующие
компьютерные платформы будут продолжать стимулировать увеличение
скоростей в окружениях локальных сетей по мере того, как они будут
делать возможными новые высокоскоростные прикладные задачи.
Уже разработаны линии глобальных сетей (WAN) с более высокой
пропускной способностью, чтобы соответствовать постоянно
растущим скоростям LAN и сделать возможным увеличение протяженности
канала универсальной вычислительной машины через глобальные сети.
Технологии WAN, такие как Frame Relay (Реле блока данных),
Switched Multimegabit Data Service (SMDS) (Обслуживание
переключаемых мультимегабитовых информационных каналов), Synchronous
Optical Network (Sonet) (Синхронная оптическая сеть) и Broadband
Integrated Services Digital Network (Broadband ISDN, или просто
BISDN) (Широкополосная цифровая сеть с интегрированными услугами),
использовали преимущества новых цифровых и волоконно-оптических
технологий для того, чтобы обеспечить WAN иную роль, чем роль узкого
бутылочного горлышка в сквозной передаче через большие географические
пространства. Дополнительная информация по Frame Relay и SMDS
приведена соответственно в Главе 14
и Главе 15 .
С достижением более высоких скоростей в окружениях как локальных,
так и глобальных сетей, насущной необходимостью стал интерфейс
data terminal equipment (DTE)/data circuit-terminating
equipment (DCE) (Интерфейс "терминальное оборудование/оборудование
завершения работы информационной цепи"), который мог бы соединить эти
два различных мира и не стать при этом узким бутылочным
горлышком. Стандарты классических интерфейсов DTE/DCE, таких как
RS-232 и V.35, не способны обеспечить скорости Т3 или аналогичные
им скорости. К концу 1980 гг. стало очевидно, что необходим новый
протокол DTE/DCE.
High-Speed Serial Interface (HSSI) (Высокоскоростной последовательный
интерфейс) является интерфейсом DTE/DCE, разработанным компаниями
Cisco Systems и T3Plus Networking, чтобы удовлетворить перечисленные
выше потребности. Спецификация HSSI доступна для любой организации,
которая хочет реализовать HSSI. Пока что распределено свыше 150 копий
этой спецификации, и десятки компаний либо уже реализовали одно из
технических решений HSSI, либо находятся в стадии реализации. Менее
чем за 3 года HSSI стала настоящим промышленным стандартом.
В настоящее время HSSI находится в стадии процесса официальной
стандартизации в комитете Ассоциации электронной промышленности
(EIA/TIATR30.2) Американскогo национальногo институтa стандартизации
(ANSI). Недавно он был передан в организации "Международный
Консультативный Комитет по Телеграфии и Телефонии" (CCITT) и
"Международная Организация по Стандартизации" (ISO); ожидается,
что он будет стандартизирован обеими организациями.
Основы технологии
HSSI определяет как электрический, так и и физический интерфейсы
DTE/DCE. Следовательно, он соответствует физическому уровню
эталонной модели OSI. Технические характеристики HSSI обобщены на
Рис. 9-1.
| Max. signal rate | 52 Mbps |
| Max. cable length | 50 feet |
| Connector pins | 50 |
| Interface | DTE-DCE |
| Electrical technology | Differential ECL |
| Typical power consumption | 610 mW |
| Topology | Point-to-point |
| Cable type | Shielded twisted pair |
Figure 9-1 HSSI Technical Characteristics
Максимальная скорость передачи сигнала HSSI равна 52 Mb/сек. На
этой скорости HSSI может оперировать скоростями Т3 (45 Mb/сек)
большинства современных быстродействующих технологий WAN, скоростями
Office Channel (OC)-1 (52 Mb/сек) иерархии синхронной цифровой сети
(SDN), а также может легко обеспечить высокоскоростное соединение
между локальными сетями, такими, как Token Ring и Ethernet.
Применение дифференциальных логических схем с эмиттерным
повторителем (ЕCL) позволяет HSSI добиться высоких скоростей передачи
информации и низких уровней помех. ECL использовалась в интерфейсах
Cray в течение нескольких лет; эта схема определена
стандартом сообщений High-Perfomance Parallel Interface (HIPPI),
разработанным ANSI, для связей LAN с суперкомпьютерами. ECL-это
имеющаяся в готовом виде технология, которая позволяет превосходно
восстанавливать синхронизацию приемника, результатом чего является
достаточный запас надежности по синхронизации.
Гибкость синхронизации и протокола обмена информацией HSSI делает
возможным выделение полосы пропускания пользователю (или поставщику).
DCE управляет синхронизацией путем изменения ее скорости или путем
стирания импульсов синхронизации. Таким образом DCE может распределять
полосу пропускания между прикладными задачами. Например, PВX может
потребовать одну величину полосы пропускания, роутер
другую величину, а расширитель канала-третью. Распределение полосы
пропускания является ключом для того, чтобы сделать Т3 и другие
услуги широкой полосы (broadband) доступными и популярными.
HSSI использует субминиатюрный, одобренный FCC 50-контактный
соединитель, размеры которого меньше, чем у его аналога V.35. Чтобы
уменьшить потребность в адаптерах для соединения двух вилок или двух
розеток, соединители кабеля HSSI определены как вилки. Кабель HSSI
использует такое же число контактов и проводов, как кабель интерфейса
Small Computer Systems Interface 2 (SCSI-2), однако технические
требования HSSI на электрические сигналы более жесткие.
Для любого из высших уровней диагностического ввода, HSSI обеспечивает
четыре проверки петлевого контроля. Эти тесты показаны на Рис. 9-2
"четыре теста петлевого контроля HSSI". Первый тест обеспечивает
контроль кабеля локальной сети, т.к. сигнал закольцовывается, как
только он доходит до порта DTE. Сигнал второго теста доходит до
линейного порта локального DСE. Сигнал трeтьего теста доходит до
линейного порта отдаленной DCE. И наконец, четвертый тест представляет
собой инициируемую DCE проверку устройством DTE порта DCE.

HSSI предполагает, что DCE и DТЕ обладают одинаковым интеллектом.
Протокол управления упрощен, т.к. требуется всего два управляющих
сигнала (DTE available - "DTE доступен" и
DCE available - "DCE доступен").
Оба сигнала должны быть утверждены до того, как информационная цепь
станет действующей. Ожидается, что DTE и DCE будут в состоянии
управлять теми сетями, которые находятся за их интерфейсами.
Уменьшение числа управляющих сигналов улучшает надежность цепи за
счет уменьшения числа цепей, которые могут отказать.
[]
[]
[]
Библиографическая справка
В конце 1980 гг. Internet (крупная международная сеть, соединяющая
множество иссследовательских организаций, университетoв и
коммерческих концернов) начала испытывать резкий рост числа главных
вычислительных машин, обеспечивающих TCP/IP. Преобладающая часть
этих главных вычислительных машин была подсоединена к локальным сетям
(LAN) различных типов, причем наиболее популярной была Ethernet.
Большая часть других главных вычислительных машин.соединялись через
глобальные сети (WAN), такие как общедоступные сети передачи данных
(PDN) типа Х.25. Сравнительно небольшое число главных вычислительных
машин были подключены к каналам связи с непосредственным (двухточечным)
соединением (т.е. к последовательным каналами связи). Однако каналы
связи с непосредственным соединением принадлежат к числу старейших
методов передачи информации, и почти каждая главная вычислительная
машина поддерживает непосредственные соединения. Например, асинхронные
интерфейсы RS-232-С встречаются фактически повсюду.
Одной из причин малого числа каналов связи IP с непосредственным
соединением было отсутствие стандартного протокола формирования
пакета данных Internet. Протокол Point-to-Point Protocol (PPP)
(Протокол канала связи с непосредственным соединением) предназначался
для решения этой проблемы. Помимо решения проблемы формирования
стандартных пакетов данных Internet IP в каналах с непосредственным
соединением, РРР также должен был решить другие проблемы, в том числе
присвоение и управление адресами IP, асинхронное (старт/стоп) и
синхронное бит-ориентированное формирование пакета данных,
мультиплексирование протокола сети, конфигурация канала
связи, проверка качества канала связи, обнаружение ошибок и
согласование варианта для таких способностей, как согласование
адреса сетевого уровня и согласование компрессии информации. РРР
решает эти вопросы путем обеспечения расширяемого Протокола
Управления Каналом (Link Control Protocol) (LCP) и семейства
Протоколов Управления Сетью (Network Control Protocols) (NCP),
которые позволяют согласовывать факультативные параметры конфигурации
и различные возможности. Сегодня PPP, помимо IP, обеспечивает также
и другие протоколы, в том числе IPX и DECnet.
Канальный уровень PPP
РРР использует принципы, терминологию и структуру блока данных
процедур HDLC (ISO 3309-1979) Международной Организации по
Стандартизации (ISO), модифицированных стандартом ISO
3309-1984/PDAD1 "Addendum 1:Start/stop Trasmission"
(Приложение 1:
Стартстопная передача"). ISO 3309-1979 определяет структуру блока
данных HLDC для применения в синхронных окружениях.
ISO 3309-1984/PDAD1 определяет предложенные для стандарта
ISO 3309-1979 модификации, которые позволяют его использование в
асинхронных окружениях. Процедуры управления РРР используют дефиниции
и кодирование управляющих полей, стандартизированных ISO 4335-1979 и
ISO 4335-1979/Addendum 1-1979.
Нa Рис. 10-1 приведен формат блока данных РРР.

flag
Длина последовательности "флаг" равна одному байту; она указывает
на начало или конец блока данных. Эта последовательность состоит
из бинарной последовательности 01111110.
address
Длина поля "адрес" равна 1 байту; оно содержит бинарную
последовательность 11111111, представляющую собой стандартный
широковещательный адрес. РРР не присваивает индивидуальных адресов
станциям.
control
Поле "управление" составляет 1 байт и содержит бинарную
последовательность 00000011, которая требует от пользователя
передачи информации непоследовательным кадром. Предусмотрены услуги
без установления соединения канала связи, аналогичные услугам
LLC Type 1. Подробную информацию о типах LLC и блоков данных смотри
в Главе 12 .
protocol
Длина поля "протокол" равна 2 байтам; его значение идентифицирует
протокол, заключенный в информационном поле блока данных.
Большинство современных значений поля протокола определены в
последнем выпуске Assigned Numbers Request for Comments (RFC).
data
Длина поля "данные" - от нуля и больше; оно содержит дейтаграмму для
ротокола, заданного в поле протокола. Конец информационного поля
определяется локализацией замыкающей последовательности "флаг" и
предоставлением двух байтов полю FCS. Максимальная длина умолчания
информационного поля равна 1500 байтам. В соответствии с априорным
соглашением, разрешающие реализации РРР могут использовать другие
значения максимальной длины информационного поля.
frame check sequence
Поле проверочной последовательности блока данных (FCS) обычно
составляет 16 бит (два байта). В соответствии с априорным соглашением,
разрешающие реализации РРР могут использовать 32-х битовое
(четырехбайтовое) поле FCS, чтобы улучшить процесс выявления
ошибок.
Link Control Protocol (LCP) может согласовывать модификации
стандартной структуры блока
данных РРР. Однако модифицированные блоки данных всегда будут
четко различимы от стандартных блоков данных.
Компоненты PPP
РРР обеспечивает метод передачи дейтаграмм через последовательные
каналы связи с непосредственным соединением. Он содержит три
основных компонента:
Метод формирования дейтаграмм для передачи по последовательным
каналам. РРР использует протокол High-level Data Link Control
(HDLC) (Протокол управления каналом передачи данных высокого
уровня)
в качестве базиса для формирования дейтаграмм при прохождении через
каналы с непосредственным соединением. Дополнительная информация по
HDLC дается в Главе 12
.
Расширяемый протокол LCP для организации, выбора конфигурации
и проверки соединения канала передачи данных.
Семейство протоколов NCP для организации и выбора конфигурации
различных протоколов сетевого уровня. РРР предназначена для
обеспечения одновременного пользования множеством протоколов
сетевого уровня.
Основные принципы работы
Для того, чтобы организовать связь через канал связи с непосредственным
соединением, инициирующий РРР сначала отправляет пакеты LCР для выбора
конфигурации и (факультативно) проверки канала передачи данных.
После того, как канал установлен и пакетом LCР проведенo необходимое
согласование факультативных средств, инициирующий РРР отправляет пакеты
NCP, чтобы выбрать и определить конфигурацию одного или более протоколов
сетевого уровня. Как только конфигурация каждого выбранного протокола
определена, дейтаграммы из каждого протокола сетевого уровня
могут быть отправлены через данный канал. Канал сохраняет свою
конфигурацию для связи до тех пор, пока явно выраженные пакеты
LCP или NCP не закроют этот канал, или пока не произойдет какое-нибудь
внешнее событие (например, истечет срок бездействия таймера или
вмешается какой-нибудь пользователь).
Протокол управления канала связи PPP (LCP)
LCP обеспечивает метод организации, выбора конфигурации, поддержания
и окончания работы канала с непосредственным соединением. Процесс LCD
проходит через 4 четко различаемые фазы:
Организация канала и согласование его конфигурации. Прежде чем
может быть произведен обмен каких-либо дейтаграмм сетевого уровня
(например, IP), LCP сначала должен открыть связь и согласовать
параметры конфигурации. Эта фаза завершается после того, как пакет
подтверждения конфигурации будет отправлен и принят.
Определение качества канала связи. LCP обеспечивает
факультативную фазу определения качества канала, которая следует за
фазой организации канала и согласования его конфигурации. В этой фазе
проверяется канал, чтобы определить, является ли качество канала
достаточным для вызова протоколов сетевого уровня. Эта фаза
является полностью факультативной. LСP может задержать передачу
информации протоколов сетевого уровня до завершения этой фазы.
Согласование конфигурации протоколов сетевого уровня. После того,
как LСP завершит фазу определения качества канала связи, конфигурация
сетевых протоколов может быть по отдельности выбрана соответствующими
NCP, и они могут быть в любой момент вызваны и освобождены для
последующего использования. Если LCP закрывает данный канал, он
информирует об этом протоколы сетевого уровня, чтобы они могли
принять соответствующие меры.
Прекращение действия канала. LCP может в любой момент закрыть
канал. Этро обычно делается по запросу пользователя (человека),
но может произойти и из-за какого-нибудь физического события,
такого, как потеря носителя или истечение периода бездействия
таймера.
Существует три класса пакетов LCP:
Пакеты для организации канала связи. Используются для организации
и выбора конфигурации канала.
Пакеты для завершения действия канала. Используются для завершения
действия канала связи.
Пакеты для поддержания работоспособности канала. Используются для
поддержания и отладки канала.
Эти пакеты используются для достижения работоспособности каждой
из фаз LCP.
[]
[]
[]
Требования, определяемые физическим уровнем
РРР может работать через любой интерфейс DTE/DCE (например,
EIA RS-232-C, EIA RS-422, EIA RS-423 и CCITT V.35). Единственным
абсолютным требованием, которое пред'являет РРР, является требование
обеспечения дублированных схем (либо специально назначенных, либо
переключаемых), которые могут работать как в синхронном, так и в
асинхронном последовательном по битам режиме, прозрачном для
блоков данных канального уровня РРР. РРР не пред'являет каких-либо
ограничений, касающихся скорости передачи информации, кроме тех,
которые определяются конкретным примененным интерфейсом DTE/DCE.