Библиографическая справка
NetWare является операционной системой сети (network operating
system - NOS) и связанной с ней средой обеспечения услуг,
разработанной Novell, Inc. и представленной на рынок в начале 1980 гг.
В то время сети были небольшими и преимущественно гомогенными, связь
рабочих групп с помощью локальных сетей была еще новым явлением, а
идея о персональном компьютере еще только начала завоевывать
популярность.
Большая часть технологии организации сетей NetWare была заимствована
из Xerox Network Systems (XNS) - системы организации сетей,
разработанной Xerox Corporation в конце 1970 гг. Подробная информация
о XNS приведена в
Главе 22 "".
K началу 1990 гг. доля в рынке NOS NetWare возросла до 50-75 %
(данные зависят от исследовательских групп, занимавшихся изучением
рынка). Установив свыше 500,000 сетей NetWare по всему миру
и ускорив продвижение по пути об'единения сетей с другими сетями,
NetWare и подддерживающие ее протоколы часто сосуществуют на одном и
том же физическом канале с многими другими популярными протоколами, в
том числе ТСР/IP, DECnet и AppleTalk.
Доступ к среде
NetWare работает с Ethenet/IEEE 802.3, Token Ring/IEEE 802.5, Fiber
Distributed Data Interface (FDDI) и ARCnet.
Информация о Ethernet/IEEE 802.3 дается в
Главе 5 "", о
Token Ring/IEEE 802.5 - в
Главе 6 "", o
FDDI - в Главе 7 "".
NetWare также работает в синхронных каналах глобальных сетей,
использующих Point-to-Point Protocol (PPP) (Протокол непосредственных
соединений). РРР подробно рассматривается в
Главе 10 "".
ARСnet представляет собой систему простой сети, которая поддерживает
все три основных носителя (скрученную пару, коаксиальный кабель и
волоконно-оптический кабель) и две топологии (шина и звезда). Она
была разработана корпорацией Datapoint Corporation и выпущена в 1977.
Хотя ARCnet не приобрела такую популярность, какой пользуются
Ethernet и Token Ring, ее гибкость и низкая стоимость завоевали много
верных сторонников.
Основы технологии
В качестве среды NOS, NetWare определяет пять высших уровней
эталонной модели OSI. Она обеспечивает совместное пользование файлами
и принтером, поддержку различных прикладных задач, таких как передача
электронной почты и доступ к базе данных, и другие услуги. Также, как и
другие NOS, такие как Network File System (NFS) компании Sun
Microsystems, Inc. и LAN Manager компании Microsoft Corporation,
NetWare базируется на архитектуре клиент-сервер
(slient-server architecture). В таких архитектурах клиенты (иногда
называемые рабочими станциями) запрашивают у серверов
определенные услуги, такие как доступ к файлам и принтеру.
Первоначально клиентами NetWare были небольшие РС, в то время как
серверами были ненамного более мощные РС. После
того, как NetWare стала более популярной, она была перенесена на
другие компьютерные платформы. В настоящее время клиенты и сервера
могут быть представлены практически любым видом
компьютерной системы, от РС до универсальных вычислительных машин.
Основная характеристика системы клиент-сервер
заключается в том, что доступ к отдаленной сети является прозрачным для
пользователя. Это достигается с помощью удаленного вызовова процедур
(remote procedure calls) - такого процесса, когда
программа местного компьютера, работающая на оборудовании клиента,
отправляет вызов в удаленный сервер. Этот сервер
выполняет указанную процедуру и
возвращает запрошенную информацию клиенту местного компьютера.
Рис. 19-1 иллюстрирует в упрощенном виде известные протоколы
NetWare и их связь с эталонной моделью OSI. При наличии соответствующих
драйверов, NetWare может работать с любым протоколом доступа к
носителю. На рисунке перечислены те протоколы доступа к носителю,
которые в настоящее время обеспечиваются драйверами NetWare.
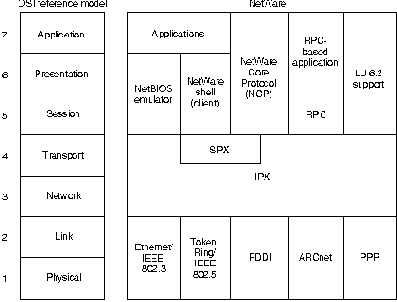
Протоколы высших уровней
NetWare поддерживает большое разнообразие протоколов высших уровней;
некоторые из них несколько более популярны, чем другие. NetWare shell
(командный процессор) работает в оборудовании клиентов (которое часто
называется рабочими станциями среди специалистов по NetWare) и
перехватывает обращения прикладных задач к устройству Ввод/Вывод,
чтобы определить, требуют ли они доступ к сети для удовлетворения
запроса. Если это так, то NetWare shell организует пакеты запросов и
отправляет их в программное обеспечение низшего уровня для обработки и
передачи по сети. Если это не так, то они просто передаются в ресурсы
местного устройства Ввода/Вывода. Прикладные задачи клиента не
осведомлены о каких-либо доступах к сети, необходимых для выполнения
обращений прикладных задач. NetWare Remote Procedure Call (Netware
RPC) (Вызов процедуры обращения к отдаленной сети) является еще
одним более общим механизмом переадресации, поддерживаемым Novell.
Netware Core Protocol (NCP) (Основной протокол NetWare) представляет
собой ряд программ для сервера, предназначенных для
удовлетворения запросов прикладных задач, приходящих, например, из
NetWare shell. Услуги, предоставляемые NCP, включают доступ к файлам,
доступ к принтеру, управление именами, учет использования ресурсов,
защиту данных и синхронизацию файлов.
NetWare также поддерживает спецификацию интерфейса сеансового
уровня Network Basic I/O System (NetBIOS) компаний IBM и Microsoft.
Программа эмуляции NetBIOS, обеспечиваемая NetWare, позволяет
программам, написанным для промышленного стандартного интерфейса
NetBIOS, работать в пределах системы NetWare.
Услуги прикладного уровня NetWare включают
NetWare Message Handling Service (NetWare MHS)
(Услуги по обработке сообщений),
Btrieve,
NetWare Loadable Modules (NLM) (Загружаемые модули NetWare)
и различные
характеристики связности IBM. NetWare MHS является системой доставки
сообщений, которая обеспечивает транспортировку электронной почты.
Btrieve представляет собой реализацию механизма доступа к базе данных
двоичного дерева (btree) Novell. NLM реализуются как дополнительные
модули, которые подключаются к системе NetWare. В настоящее время
компания Novell и третьи участвующие стороны предоставляют NLM
для чередующихся комплектов протоколов (alternate protocol stacks),
услуги связи, услуги доступа
к базе данных и много других услуг.
[]
[]
[]
Сетевой уровень
Internet Packet Exchange (IPX) является оригинальным протоколом
сетевого
уровня Novell. Если устройство, с которым необходимо установить
связь, находится в другой сети, IPX прокладывает маршрут для
прохождения информации через любые промежуточные сети, которые могут
находиться на пути к пункту назначения. На Рис. 19-2 представлен
формат пакета IPX.
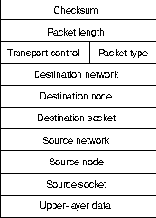
Пакет IPX начинается с 16-битового поля контрольной суммы (checksum),
которое устанавливается на единицы.
16-битовое поле длины (length) определяет длину полной дейтаграммы
IPX в байтах. Пакеты IPX могут быть любой длины, вплоть до размеров
максимальной единицы передачи носителя (MTU). Фрагментация
пакетов не применяется.
За полем длины идет 8-битовое поле управления транспортировкой
(transport control), которое обозначает число роутеров, через
которые прошел пакет. Когда значение этого поля доходит до 15,
пакет отвергается исходя из предположения, что могла иметь место
маршрутная петля.
8-битовое поле типа пакета (packet type) определяет протокол высшего
уровня для приема информации пакета. Двумя общими значениями этого
поля являются 5, которое определяет Sequenced Packet Exchange (SPX)
(Упорядоченный обмен пакетами) и 17, которое определяет NetWare Core
Protocol (NCP) (Основной протокол NetWare).
Информация адреса пункта назначения (destination address) занимает
следующие три поля. Эти поля определяют сеть, главную вычислительную
машину и гнездо (процесс) пункта назначения.
Следом идут три поля адреса источника (source address), определяющих
сеть, главную вычислительную машину и гнездо источника.
За полями пункта назначения и источника следует поле данных (data).
Оно содержит информацию для процессов высших уровней.
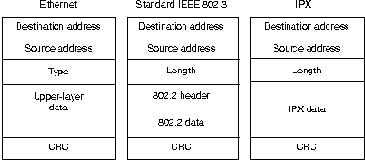
Хотя IPX и является производной XNS, он имеет несколько уникальных
характеристик. С точки зрения маршрутизации , наиболее важное
различие заключается в механизмах формирования пакетов данных этих
двух протоколов. Формирование пакета данных - это процесс упаковки
информации протокола высшего уровня и данных в блок данных. Блоки
данных являются логическими группами информации, очень похожими на
слова телефонного разговора. XNS использует стандартное формирование
блока данных Ethernet, в то время как пакеты IPX формируются в блоки
данных Ethernet Version 2.0 или IEEE 802.3 без информации IEEE 802.2,
которая обычно сопровождает эти блоки данных. Рис.19-3 иллюстрирует
формирование пакета данных Ethernet, стандарта IEEE 802.3 и IPX.
Примечание: NetWare 4.0 обеспечивает формирование пакетов IPX
в блоки данных IEEE 802.3.
Для маршрутизации пакетов в об'единенных сетях IPX использует протокол
динамической маршрутизации, называемый Routing Information Protocol
(RIP) (Протокол маршрутной информации). Также, как и XNS, RIP получен
в результате усилий компании Xerox по разработке семейства протоколов
XNS. В настоящее время RIP является наиболее часто используемым
протоколом для внутренних роутеров (interior gateway protocol-IGP) в
сообществе Internet-среде международной сети, обеспечивающей связность
практически со всеми университетами и исследовательскими институтами
и большим числом коммерческих организаций в США, а также со многими
иностранными организациями. Подробная информация о RIP приведена в
Главе 23 "".
В дополнение к разнице в механизмах формирования пакетов, Novell также
дополнительно включила в свое семейство протоколов IPX протокол,
называемый Service Adverticement Protocol (SAP) (Протокол об'явлений
об услугах). SAP позволяет узлам, обеспечивающим услуги, об'являть
о своих адресах и услугах, которые они обеспечивают.
Novell также поддерживает "Блок адресуемой сети" LU 6.2 компании
IBM (LU 6.2 network addressable unit - NAU). LU 6.2 обеспечивает
связность по принципу равноправных систем через среду сообщений IBM.
Используя возможности LU 6.2, которые имеются у NetWare, узлы
NetWare могут обмениваться информацией через сеть IBM. Пакеты
NetWare формируются в пределах пакетов LU 6.2 для передачи через
сеть IBM.
Транспортный уровень
Sequenced Packet Exchange (SPX) (Упорядоченный обмен пакетами)
является наиболее часто используемым протоколом транспортного
уровня NetWare. Novell получила этот протокол в результате доработки
Sequenced Packet Protocol (SPP) системы XNS. Как и протокол ТСР
(Transmission Control Protocol) и многие другие протоколы
транспортного уровня, SPX является надежным, с установлением
соединения протоколом, который дополняет услуги дейтаграмм,
обеспечиваемые протоколами Уровня 3.
Novell также предлагает поддержку протокола Internet Protocol (IP)
в виде формирования протоколом User Datagram Protocol(UDP)/IP других
пакетов Novell, таких как пакеты SPX/IPX. Для транспортировки
через об'единенные сети, базирующиеся на IP, дейтаграммы IPX
формируются внутри заголовков UDP/IP. Общая информация о протоколах
UPD и Internet дается в
Главе 18 "".
Адресация
Услуги сети OSI предоставляются транспортному уровню через
концептуальную точку на границе сетевого и транспортного уровней,
известную под названием "точки доступа к услугам сети" (network
service access point - NSAP). Для каждого об'екта транспортного
уровня имеется одна NSAP.
Каждая NSAP может быть индивидуально адресована в об'единенной
глобальной сети с помощью адреса NSAP (в обиходе существует неточное
название - просто NSAP). Таким образом, любая конечная система OSI
имеет, как правило, множество адресов NSAP. Эти адреса обычно
отличаются только последним байтом, называемом n-selector.
Возможны случаи, когда полезно адресовать сообщение сетевому уровня
системы в целом, не связывая его с конкретным об'ектом транспортного
уровня, например, когда система участвует в протоколах маршрутизации
или при адресации к какой-нибудь промежуточной системе
(к роутеру). Подобная адресация выполняется через специальный
адрес сети, известный под названием network entity title (NET)
(титул об'екта сети). Структурно NET идентичен адресу NSAP, но он
использует специальное значение n-selector "00". Большинство конечных
и промежуточных систем имеют только один NET, в отличие от
роутеров IP, которые обычно имеют по одному адресу на каждый
интерфейс. Однако промежуточная система, участвующая в нескольких
областях или доменах, имеет право выборa на обладание несколькими
NET.
Адреса NET и NSAP являются иерархическими адресами. Адресация к
иерархическим системам облегчает как управление (путем обеспечения
нескольких уровней управления), так и маршрутизацию (путем кодирования
информации о топологии сети). Адрес NSAP сначала разделяется на две
части: исходная часть домена (initial domain part - IDP) и специфичнaя
часть домена (domain specific part - DSP).
IDP далее делится на идентификатор формата и
полномочий (authority and format identifier - AFI) и идентификатор
исходного домена (initial domain identifier - IDI).
AFI обеспечивает информацию о структуре и содержании полей IDI и DSP,
в том числе информацию о том, является ли IDI идентификатором
переменной длины и использует ли DSP десятичную или двоичную
систему счислений. IDI определяет об'ект, который может назначать
различные значения части DSP адреса.
DSP далее подразделяется полномочным лицом, ответственным за ее
управление. Как правило, далее следует идентификатор другого
управляющего авторитета, чем обеспечивается дальнейшее делегирование
управления адресом в подорганы управления. Далее идет
информация, используемая для маршрутизации, такая, как домены
маршрутизации, область (area) с доменом маршрутизации, идентификатор
(ID) станции в пределах этой области и селектор (selector) в пределах
этой станции. Рис. 20-2 иллюстрирует формат адреса OSI.

Библиографическая справка
В первые годы появления межкомпьютерной связи программное обеспечение
организации сетей создавалось бессистемно, для каждого отдельного
случая. После того, как сети приобрели достаточную популярность,
некоторые из разработчиков признали необходимость стандартизации
сопутствующих изделий программного обеспечения и разработки аппаратного
обеспечения. Считалось, что стандартизация позволит поставщикам
разработать системы аппаратного и программного обеспечения, которые
смогут сообщаться друг с другом даже в том случае, если в их основе
лежат различные архитектуры. Поставив перед собой эту цель, ISO начала
разработку эталонной модели Open Systems Interconnections (OSI)
(Взаимодействие открытых систем). Эталонная модель OSI была завершена
и выпущена в 1984 г.
В настоящее время эталонная модель OSI (подробно рассмотренная в
Главе 1 " )
является самой
выдающейся в мире моделью архитектуры об'единенных сетей. Она также
является самым популярным средством приобретения знаний о сетях.
С другой стороны, у протоколов OSI был длинный период созревания.
И хотя известно о некоторых реализациях OSI, протоколы OSI все еще
не завоевали той популярности, которой пользуются многие патентованные
протоколы (например, DECnet и АppleTalk) и действующие стандарты
(например, протоколы Internet).
Доступ к среде
Также, как и некоторые другие современные 7-уровневые комплекты
протоколов, комплект OSI включает в себя многие популярные сегодня
протоколы доступа к носителю. Это позволяет другим комплектам
протоколов существовать наряду с OSI в одном и том же носителе. В
OSI входят IEEE 802.2, IEEE 802.3, IEEE 802.5, FDDI, X.21, V.35, X.25
и другие. Большинство из этих протоколов доступа к носителю OSI уже
рассматривались в данной книге.
Основы технологии
Об'единение сетей OSI использует уникальную терминологию.
End system (ES)
Термин "конечная система" относится к любому
устройству сети, не занимающемуся маршрутизацией.
Intermediate system (IS)
Термин "промежуточная система" относится к роутеру.
Area
"Область" обозначает группу смежных сетей и подключенных
к ним хостов; область назначается
администратором сети или другим аналогичным лицом.
Domain
"Домен" представляет собой набор соединенных областей.
Домены маршрутизации обеспечивают полную связность со всеми конечными
системами, находящимися в их пределах.
Представительный уровень
Представительный уровень OSI, как правило, является просто проходным
протоколом для информации из соседних уровней. Хотя многие считают,
что Abstract Syntax Notation 1 (ASN.1) (Абстрактное представление
синтаксиса) является протоколом представительного уровня OSI, ASN.1
используется для выражения форматов данных в независимом от машины
формате. Это позволяет осуществлять связь между прикладными задачами
различных компьютерных систем способом, прозрачным для этих прикладных
задач.
Прикладной уровень
Прикладной уровень ОSI включает действующие протоколы прикладного
уровня, а также элементы услуг прикладного уровня (application service
elements - ASE). ASE обеспечивают легкую связь протоколов прикладного
уровня с низшими уровнями. Тремя наиболее важными ASE являются Элемент
услуг управления ассоциацией (Association Control Service Element -
ACSE), Элемент услуг получения доступа к операциям отдаленного
устройства (Remote Operations Service Element - ROSE) и Элемент услуг
надежной передачи (Reliable Transfer Service Element - RTSE). При
подготовке к связи между двумя протоколами прикладного уровня
ACSE об'единяет их имена друг с другом. ROSE реализует родовой
(generic) механизм "запрос/ответ", который разрешает доступ к операциям
отдаленного устройства способом, похожим на вызовы процедуры обращений
к отделенной сети (remote procedure calls - RPC). RTSE способствует
надежной доставке, делая конструктивные элементы сеансового уровня
легкими для использования.
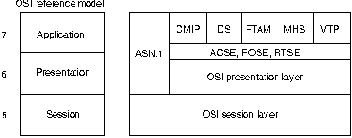
Наибольшего внимания заслуживают следующие пять протоколов прикладного
уровня OSI:
Common Management Information Protocol (CMIP)
Протокол общей информации управления - протокол управления сети OSI
Также, как и SNMP
(смотри Главу 32 "")
и Net View (смотри
Главу 33 ""),
он обеспечивает обмен управляющей
информацией между ES и станциями управления (которые также являются
ES).
Directory Services (DS)
Услуги каталогов. Разработанная на основе спецификации Х.500
CITT, эта услуга предоставляет возможности распределенной базы
анных, которые полезны для идентификации и адресации узлов высших
ровней.
File Transfer,Access, and Management (FTAM)
Передача, доступ и управление файлами - услуги по передаче
файлов. В дополнение к классической передаче файлов, для которой FTAM
обеспечивает многочисленные опции, FTAM также обеспечивает средста
доступа к распределенным файлам таким же образом, как это делает
NetWare компании Novell, Inc или Network File System (NFS)
компании Sun Microsystems, Inc.
Massage Handling Systems (MHS)
Системы обработки сообщений - обеспечивает механизм, лежащий
в основе транспортировки данных для прикладных задач передачи
сообщений по электронной почте и других задач, требующих услуг по
хранению и продвижению данных. Хотя они и выполняют аналогичные
задачи, MHS не следует путать с NetWare MHS компании Novell (смотри
Главу 19 ")".
Virtual Terminal Protocol (VTP)
Протокол виртуальных терминалов - обеспечивает
эмуляцию терминалов.
Другими словами, он позволяет компьютерной системе для
отдаленной ES казаться непосредственно подключенным терминалом.
С помощью VTP пользователь может, например, выполнять дистанционные
работы на универсальных вычислительных машинах.
[]
[]
[]
Протоколы высших уровней
Основные протоколы высших уровней OSI представлены на Рис. 20-3.
Сеансовый уровень
Протоколы сеансового уровня OSI преобразуют в сеансы потоки данных,
поставляемых четырьмя низшими уровнями, путем реализации
различных управляющих механизмов. В число этих механизмов входит
ведение учета, управление диалогом (т.е. определение, кто и когда
может говорить) и согласование параметров сеанса.
Управление диалогом сеанса реализуется путем использования маркера
(token), обладание которым обеспечивает право на связь. Маркер можно
запрашивать, и конечным системам ES могут быть присвоены приоритеты,
обеспечивающие неравноправное пользование маркером.
Сетевой уровень
OSI предлагает услуги сетевого уровня как без установления соединения,
так и ориентированные на установления логического соединения.
Услуги без установления соединения
описаны в ISO 8473 (обычно называемом Connectionless Network
Protocol - CLNP - Протокол сети без установления соединения).
Обслуживание, ориентированное на установление логического соединения
(иногда называемое
Connection-Oriented Network Service - CONS) описывается в ISO 8208
(X.25 Packet-Level Protocol - Протокол пакетного уровня X.25,
иногда называемый Connection-Mode Network Protocol - CMNP)
и ISO 8878 (в котором
описывается, как пользоваться ISO 8208, чтобы обеспечить
ориентированные на установление логического соединения услуги OSI).
Дополнительный документ
ISO 8881 описывает, как обеспечить работу Протокола пакетного уровня
X.25 в локальных сетях IEEE 802. OSI также определяет несколько
протоколов маршрутизации, которые рассмотрены в
Главе 28 "".
X.25 рассмотрен в Главе 13 "".
В дополнение к уже упоминавшимся спецификациям протоколов и услуг,
имеются другие документы, связанные с сетевым уровнем OSI, в число
которых входят:
ISO 8648
На этот документ обычно ссылаются как на "внутреннюю
организацию сетевого уровня"
(internal organization of the network level - IONL).
Он описывает, каким образом можно разбить сетевой уровень
на три отдельных различимых друг от друга подуровня, чтобы обеспечить
поддержку для различных типов подсетей.
ISO 8348
Этот документ обычно называют "определение услуг сети"
(network service definition). Он описывает ориентированные
на установление логического соединения услуги
и услуги без установления соединения, которые
обеспечивает сетевой уровень OSI. Адресация сетевого уровня также
определена в этом документе. Определение услуг в режиме без
установления
соединения и определение адресации раньше были опубликованы отдельным
дополнением к ISO 8348; однако вариант ISO 8348 1993 года об'единяет
все дополнения в отдельный документ.
ISO TR 9575
Этот документ описывает структуру, концепции и
терминологию, использованную в протоколах маршрутизации OSI.
ISO TR 9577
Этот документ описывает, как отличать друг от друга
большое число протоколов сетевого уровня, работающих в одной и той
же среде. Это необходимо потому, что в отличие от других протоколов,
протоколы сетевого уровня OSI не различаются с помощью какого-либо
идентификатора (ID) протокола или аналогичного поля канального уровня.
Услуги без установления соединения
Как видно из названия, CLNP является протоколом дейтаграмм без
установления соединения, который используется для переноса данных
и указателей неисправности. По своим функциональным возможностям он
похож на Internet Protocol (IP), описанный в
Главе 18 "".
Он не содержит средств обнаружения ошибок и их коррекции,
полагаясь на способность транспортного уровня обеспечить
соответствующим образом эти услуги. Он содержит только одну фазу,
которая называется "передача информации" (data transfer).
Каждый вызов
какого-либо примитива услуг не зависит от всех других вызовов, для чего
необходимо, чтобы вся адресная информация полностью содержалась в
составе примитива.
В то время как CLNP определяет действующий протокол, выполняющий
типичные функции сетевого уровня, CLNS (Обслуживание сети без
установления соединения) описывает услуги, предоставляемые
транспортному уровню, в котором запрос о передаче информации
реализуется доставкой, выполненной с наименьшими затратами (best
effort). Такая доставка не гарантирует, что данные не будут потеряны,
испорчены, что в них не будет нарушен порядок, или что они не будут
скопированы. Обслуживание без установления соединения предполагает,
что при необходимости все эти проблемы будут устранены в транспортном
уровне. CLNS не обеспечивает никаких видов информации о соединении
или состоянии, и не выполняет настройку соединения. Т.к. CLNS
обеспечивает транспортные уровни интерфейсом услуг, сопрягающим с
CLNP, протоколы CNLS и CLNP часто рассматриваются вместе.
Транспортный уровень
Как обычно для сетевого уровня OSI, oбеспечиваются услуги как без
установления соединения, так и с установлением соединения. Фактически
имеется 5 протоколов транспортного уровня OSI с установлением
соединения: ТР0, ТР1, ТР2, ТР3 и ТР4.
Все они, кроме ТР4, работают
только с услугами сети OSI с установлением соединения. ТР4 работает с
услугами сети как с установлением соединения, так и без установления
соединения.
ТР0 является самым простым протоколом транспортного уровня OSI,
ориентированным на установления логического соединения.
Из набора классических функций протокола
транспортного уровня он выполняет только сегментацию и повторную
сборку. Это означает, что ТР0 обратит внимание на протокольную
информационную единицу (protocol data unit - PDU) с самым маленьким
максимальным размером,
который поддерживается лежащими в основе подсетями, и разобьет пакет
транспортного уровня на менее крупные части, которые не будут слишком
велики для передачи по сети.
В дополнение к сегментации и повторной сборке ТР1 обеспечивает
устранение базовых ошибок. Он нумерует все PDU и повторно
отправляет те, которые не были подтверждены. ТР1 может также повторно
инициировать соединение в том случае, если имеет место превышение
допустимого числа неподтвержденных РDU.
ТР2 может мультиплексировать и демультиплексировать потоки данных через
отдельную виртуальную цепь. Эта способность делает ТР2 особенно
полезной в общедоступных информационных сетях (PDN), где каждая
виртуальная цепь подвергается отдельной загрузке. Подобно ТР0
и ТР1, ТР2 также сегментирует и вновь собирает PDU.
ТР3 комбинирует в себе характеристики ТР1 и ТР2.
ТР4 является самым популярным протоколом транспортного уровня OSI.
ТР4 похож на протокол ТСР из комплекта протоколов Internet;
фактически, он базировался на ТСР. В дополнение к характеристикам
ТР3, ТР4 обеспечивает надежные услуги по транспортировке. Его
применение предполагает сеть, в которой проблемы не выявляются.
Услуги с установлением соединения
Услуги сети OSI с установлением соединения определяются ISO 8208 и
ISO 8878. OSI использует X.25 Racket-Level Protocol для перемещения
данных и указателей ошибок с установлением соединения. Для об'ектов
транспортного уровня предусмотрено 6 услуг (одна для установления
соединения, другая для раз'единения соединения, и четыре для
передачи данных). Услуги вызываются определенной комбинацией из 4
примитив: запрос (request), указатель (indication),
ответ (response) и подтверждение (confirmation).
Взаимодействие этих четырех
примитив показано на Рис. 20-1.
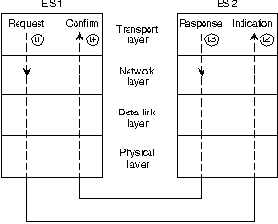
В момент времени t1 транспортный уровень ES 1 отправляет примитив-
запрос в сетевой уровень ES 1. Этот запрос помещается в подсеть ES 1
протоколами подсети низших уровней и в конечном итоге принимается
ES 2, который отправляет информацию вверх в сетевой уровень. В
мотент времени t2 сетевой уровень ES 2 отправляет примитив-указатель
в свой транспортный уровень. После завершения необходимой обработки
пакета в высших уровнях, ES 2 инициирует ответ в ES 1, используя
примитив-ответ, отправленный из транспортного уровня в сетевой
уровень. Отправленный в момень времени t3 ответ возвращается
в ES 1, который отправляет информацию вверх в сетевой уровень, где
генерируется примитив-подтверждение, отправляемый в
транспортный уровень в момент t3.
Библиографическая справка
Компания Banyan Virtual Network System (VINES) реализовала систему
распределенной сети, базирующуюся на семействе патентованных
протоколов, разработанных на основе протоколов Xerox Network Systems
(XNS) компании XEROX (смотри
главу 22 "").
Среда распределенной
системы обеспечивает прозрачный для пользователя обмен информации
между клиентами (компьютерами пользователя) и служебными устройствами
(компьютерами специального назначения, которые обеспечивают услуги,
такие, как файловое и принтерное обслуживание). Наряду с NetWare
компании Novell, LAN Server компании IBM и LAN Manager компании
Microsoft, VINES является одной из самых популярных сред распределенной
системы для сетей, базирующихся на микрокомпьютерах.
Доступ к среде
Два низших уровня комплекта протоколов VINES реализованы с помощью
различных общеизвестных механизмов доступа к носителю, включая
Управление информационным каналом высшего уровня (HDLC) (смотри Главу
12 ""),
Х.25 (смотри Главу 13 ""),
Ethernet (смотри Главу 5 "")
и Тоken Ring (смотри
Главу 6 "").
Основы технологии
Комплект протоколов VINES представлен на Рис. 21-1.
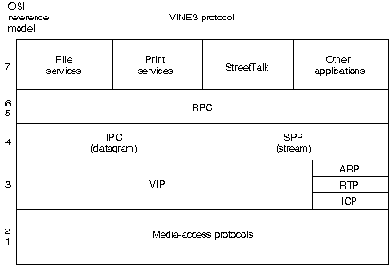
Протокол корректировки маршрутизации (RTR)
RTR распределяет информацию о топологии сети. Пакеты корректировки
маршрутизации периодически пересылаются широкой рассылкой как клиентом,
так и узлами обслуживания. Эти пакеты информируют соседей о
существовании какого-нибудь узла, а также указывают, является ли этот
узел клиентом или узлом обслуживания. В каждый пакет корректировки
маршрутизации узла обслуживания также включается перечень всех
известных сетей и коэффициенты затрат, связанные с достижением этих
сетей.
Поддерживаются две маршрутные таблицы: таблица всех известных сетей и
таблица соседей. Для узлов обслуживания таблица всех известных сетей
содержит запись данных о каждой известной сети, за исключением
собственной сети узла обслуживания. Каждая запись содержит номер сети,
показатель маршрутизации и указатель на запись данных следующей
пересылки на пути к данной сети в таблице соседей. Таблица соседей
содержит запись данных каждого узла обслуживания соседа и узла клиента.
Записи включают в себя номер сети, номер подсети, протокол доступа к
носителю (например, Ethernent), который использовался для достижения
этого узла, адрес локальной сети (если средой, соединяющей с соседом,
является локальная сеть) и показатель соседа.
RTR определяет 4 типа пакетов:
Пакеты корректировки маршрутизации.
Периодически выпускаются для
уведомления соседей о существовании какого-нибудь об'екта.
Пакеты запроса о маршрутизации.
Об'екты обмениваются ими, когда им
необходимо быстро узнать о топологии сети.
Пакеты ответа на запрос о маршрутизации.
Содержат топологическую
информацию и используются узлами обслуживания для ответа на пакеты
запроса о маршрутизации.
Пакеты переадресации маршрутизации.
Обеспечивают отправку информации
о лучших маршрутах в узлы, использующие неэффективные тракты.
Пакеты RTR имеют 4-байтовый заголовок, состоящий из однобайтового
поля типа операций (operation type), однобайтового поля типа узла
(node type), однобайтового поля типа контроллера
(controller type)
и однобайтового поля типа машины (machine type). Поле типа операций
указывает на тип пакета. Поле типа узла указывает, пришел пакет
из узла обслуживания или из необслуживающего узла. Поле типа
контроллера указывает, содержит ли контроллер узла, передающего пакет
RTR, многобуферный контроллер. Это поле используется для облегчения
регулирования информационного потока между сетевыми узлами. И наконец,
поле типа машины указывает, является ли процессор отправителя RTR
быстодействующим или нет. Как и поле типа контроллера, поле
типа машины также используется для регулирования скорости передачи.
Протокол разрешения адреса (ARP)
Об'екты протокола ARP классифицируются либо как клиенты разрешения
адреса (address resolution clients), либо как услуги разрешения адреса
(address resolution services). Клиенты разрешения адреса обычно
реализуются в узлах клиентов, в то время как услуги разрешения адреса
обычно обеспечиваются узлами обслуживания.
Пакеты ARP имеют 8-байтовый заголовок, состоящий из 2-байтового
типа пакета (packet type),
4-байтового номера сети (network number)
и 2-байтового номера подсети (subnet number).
Имеется 4 типа
пакетов: запрос-заявка (query request), который является запросом
какой-либо услуги ARP; ответ об услуге (service response), который
является ответом на запрос-заявку, запрос о присваивании адреса
(assignment request), который отправляется какой-нибудь услуге ARP
для запроса адреса об'единенной сети VINES, и ответ о присваивании
адреса (assignment response), который отправляется данной услугой ARP
в качестве ответа на запрос о присваивании адреса. Поля номера сети и
номера подсети имеют значение только в пакете ответа о присваивании
адреса.
Когда какой-нибудь клиент приступает к работе, клиенты и услуги ARP
реализуют следующий алгоритм. Сначала данный клиент отправляет широкой
рассылкой пакеты запросов-заявок. Затем каждая услуга, которая
является соседом данного клиента, отвечает пакетом ответа об услуге.
Далее данный клиент выдает пакет запроса о присваивании адреса в первую
услугу, которая ответила на его пакет запроса-заявки. Услуга отвечает
пакетом ответа о присваивании адреса, содержащем присвоенный адрес
об'единенной сети.
Протокол управления объединеной сетью (ICP)
ICP определяет пакеты уведомления об исключительных ситуациях
(exception notification) и уведомления о показателе (metric
notification). Пакеты уведомления об исключительных ситуациях
обеспечивают информацию об исключительных ситуациях сетевого уровня;
пакеты уведомления о показателе содержат информацию о последней
передаче, которая была использована для достижения узла клиента.
Уведомления об исключительной ситуации отправляются в том случае,
когда какой-нибудь пакет VIP не может быть соответствующим образом
маршрутизирован, и устанавливается подполе ошибки в поле управления
транспортировкой заголовка VIP. Эти пакеты также содержат поле,
идентифицирующее конкретную исключительную ситуацию по коду ошибки,
соответствующему этой ситуации.
Об'екты ICP в узлах обслуживания генерируют сообщения уведомления
о показателе в том случае, когда устанавливается подполе показателя
в поле управления транспортировкой заголовка VIP, и адрес пункта
назначения в пакете узла обслуживания определяет одного из соседей
этого узла обслуживания.
Протоколы высших уровней
Являясь распределенной сетью, VINES использует модель вызова
процедуры обращений к отдаленной сети (remote procedure call - RPC)
для связи между клиентами и служебными устройствами. RCP является
основой сред распределенных услуг. Протокол NetRPC (Уровни 5 и 6)
обеспечивает язык программирования высшего уровня, который позволяет
осуществлять доступ к отдаленным услугам способом, прозрачным как для
пользователя, так и для прикладной программы.
На Уровне 7 VINES обеспечивает протоколы файловых услуг и услуг
принтера, а также протокол услуг "StreetTalk name/directory".
StreetTalk,
один из протоколов с торговым знаком компании VINES, обеспечивает
службу постоянных имен в глобальном масштабе для всей об'единенной сети.
VINES также обеспечивает среду разработки интегрированных применений
при наличии нескольких операционных систем, включая DOS и UNIX. Taкая
среда разработки позволяет третьей участвующей стороне осуществлять
разработку как клиентов, так и услуг, действующих в среде VINES.
[]
[]
[]
Сетевой уровень
Для выполнения функций Уровня 3 (в том числе маршрутизации в
об'единенной сети) VINES использует Протокол межсетевого обмена VINES
(VINES Internetwork Protocol - VIP).
VINES также обеспечивает собственный
Протокол разрешения адреса (ARP), собственную версию Протокола
информации маршрутизации (Routing Information Protocol - RIP), которая
называется Протоколом корректировки маршрутизации (Routing Update
Protocol - RTP) и Протокол управления Internet (ICP), который
обеспечивает обработку исключительных состояний и специальной
информации о затратах маршрутизации. Пакеты ICP, RTP и ARP формируются
в заголовке VIP.
Протокол межсетевого обмена VINES (VIP)
Адреса сетевого уровня VINES являются 48-битовыми об'ектами,
подразделенными на сетевую (32 бита) и подсетевую (16 битов) части.
Сетевой номер можно описать как номер какого-нибудь служебного
устройства, т.к. он получается непосредственно из ключа (key)
служебного устройства (аппаратного модуля, который обозначает
уникальный номер и программные опции для данного служебного
устройства). Подсетевая часть адреса VINES лучше всего описывается
как номер хоста, т.к. он используется для
обозначения хоста в сетех VINES. Рис. 21-2
иллюстрирует формат адреса VINES.

Сетевой номер обозначает логическую сеть VINES, которая представлена
в виде двухуровневого дерева, корень которого находится в узле
обслуживания (service node). Узлы обслуживания, которыми обычно
являются служебные устройства, обеспечивают услуги резрешения адреса
и услуги
маршрутизации клиентам (client), которые являются листьями этого
дерева. Узел обслуживания назначает адреса VIP клиентам.
Когда какой-нибудь клиент включает питание, он направляет
широковещательный запрос служебным устройствам. Все служебные
устройства, которые получают этот запрос, посылают ответ. Клиент
выбирает первый ответ и запрашивает у данного служебного устройства
адрес подсети (хоста). Служебное устройство
отвечает адресом, состоящим из его собственного сетевого адреса
(полученного из его ключа), об'единенного с адресом подсети (хоста),
который он выбрал сам. Адреса подсети клиента
обычно назначаются последовательно, начиная с 8001H. Адреса подсети
служебного устройства всегда 1. Процесс выбора адреса VINES показан
на Рис. 21-3.
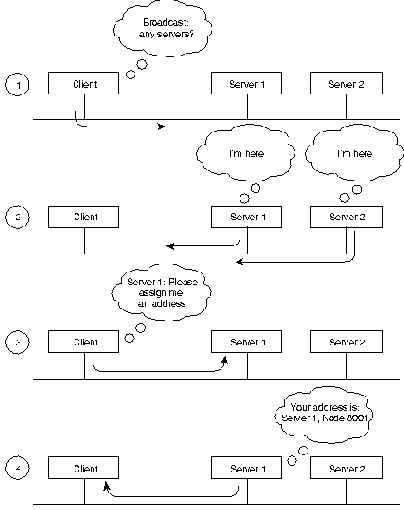
Динамичное назначение адреса не является уникальным явлением в
индустрии сетей (AppleTalk также использует этот процесс); однако
этот процесс определенно не является таким обычным процессом, как
статическое назначение адреса. Т.к. адреса выбираются исключительно
каким-нибудь одним конкретным служебным устройством (чей адрес является
уникальным вследствие уникальности аппаратного ключа), вероятность
дублирования адреса (что является потенциально опасной проблемой для
сети Internet Protocol (IP) и других сетей) очень мала.
В схеме сети VINES все служебные устройства с несколькими интерфейсами
в основном являются роутерами. Клиенты всегда выбирают свое
собственное служебное устройство в качестве роутера для первой
пересылки, даже если другое служебное устройство, подключенное к этому
же кабелю, обеспечивает лучший маршрут к конечному пункту назначения.
Клиенты могут узнать о других роутерах, получая переадресованные
сообщения от своего служебного устройства. Т.К. клиенты полагаются на
свои служебные устройства при первой пересылке маршрутизации,
служебные устройства VINES поддерживают маршрутные таблицы, которые
помогают им находить отдаленные узлы.
Маршрутные таблицы VINES состоят из пар "хост/затраты",
гдe хост соответствует сетевому
узлу, до которого можно дойти, а затраты - временной задержке в
миллисекундах, необходимой для достижения этого узла. RTP помогает
служебным устройствам VINES находить соседних клиентов, служебные
устройства и роутеры.
Все клиенты периодически об'являют как о своих адресах сетевого
уровня, так и о адресах МАС-уровня с помощью пакета, эквивалентого
пакету "hello" (приветственное сообщение).
Пакеты "hello" означают,
что данный клиент все еще работает и сеть готова. Сами служебные
устройства периодически отправляют в другие служебные устройства
маршрутные корректировки. Маршрутные корректировки извещают другие
роутеры об изменениях адресов узлов и топологии сети.
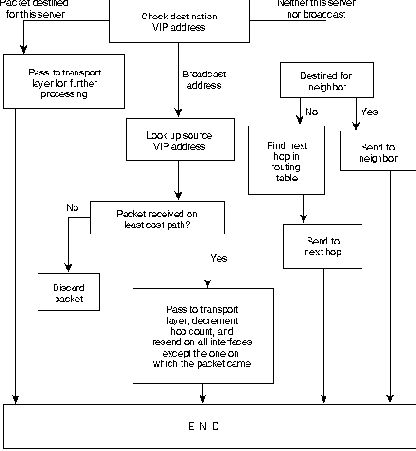
Когда какое-нибудь служебное устройство VINES принимает пакет, оно
проверяет его, чтобы узнать, для чего он предназначается - для другого
служебного устройства или для широкого вещания. Если пунктом назначения
является данное служебное устройство, то это служебное устройство
соответствующим образом обрабатывает этот запрос. Если пунктом
назначения является другое служебное устройство, то данное служебное
устройство либо непосредственно продвигает этот пакет (если это
служебное устройство является его соседом), либо направляет его в
служебное устройство/роутер, которые являются следующими в
очереди. Если данный пакет является широковещательным, то данное
служебное устройство проверяет его, чтобы узнать, пришел ли этот пакет
с маршрута с наименьшими затратами. Если это не так, то пакет
отвергается. Если же это так, то пакет продвигается на всех
интерфейсах, за исключением того, на котором этот пакет был принят.
Такой метод помогает уменьшить число широковещательных возмущений,
которые являются обычной проблемой в других сетевых окружениях.
Aлгоритм маршрутизации VINES представлен на Рис. 21-4.
Формат пакета VIP представлен на Рис. 21-5.

Пакет VIP начинается с поля контрольной суммы (checksum), используемой
для обнаружения искажений в пакете.
За полем контрольной суммы идет поле длины пакета (packet length),
которое обозначает длину всего пакета VIP.
Следующим полем является поле управления транспортировкой (transport
control), которое состоит из нескольких подполей. Если пакет является
широковещательным, то предусматривается два подполя: подполе класса
(class) (с 1 по 3 биты) и подполе числа пересылок (hop-count)
(с 4 по 7 биты). Если пакет не является широковещательным пакетом, то
предусматривается 4 подполя: подполе ошибки (error), подполе
показателя (metric), подполе переадресации (redirect),
и подполе
числа пересылок (hop count). Подполе класса определяет тип узла,
который должен принимать широковещательное сообщение. С этой целью узлы
разделяются на несколько различных категорий, зависящих от типа узла и
типа канала, к которому принадлежит узел. Определяя тип узлов, которые
должны принимать широковещательные сообщения, подполе класса
уменьшает вероятность срывов в работе, вызываемых широковещательными
сообщениями. Подполе числа пересылок представляет собой число пересылок
(число пересеченных роутеров), через которые прошел пакет.
Подполе ошибок определяет, надо ли протоколу ICP отправлять пакет
уведомления об исключительной ситуации в источник пакета, если пакет
окажется немаршрутизируемым. Подполе показателя устанавливается в 1
транспортным об'ектом, когда ему необходимо узнать затраты
маршрутизации при перемещения пакетов между каким-нибудь узлом
обслуживания и одним из соседей. Подполе переадресации определяет,
должен ли роутер генерировать сигнал переадресации (при
соответствующих обстоятельствах).
Далее идет поле типа протокола (protocol type),
указывающее на протокол
сетевого или транспортного уровня, для которого предназначен пакет
показателя или пакет уведомления об исключении.
За полем типа протокола следуют адресные поля VIP. За полями номера
сети назначения (destination network number) и номера подсети
назначения (destination subnetwork number) идут поля номера сети
источника (sourсe network number) и номера подсети источника (source
subnetwork number).
Транспортный уровень
VINES обеспечивает три услуги транспортного уровня:
Unreliable datagram service.
Услуги ненадежных дейтаграмм.
Отправляет пакеты, которые маршрутизируются на основе принципа
"наименьших затрат" (best-effort basis),
но не подтверждаются
сообщением о приеме в пункте назначения.
reliable datagram service.
Услуги надежных дейтаграмм.
Услуга виртуальной цепи, которая обеспечивает надежную
упорядоченную доставку
сообщений между узлами сети с подтверждением о приеме. Надежное
сообщение может быть передано с максимальным числом пакетов, равным 4.
data stream service.
Услуга потока данных.
Поддерживает контролируемый поток данных между двумя процессами.
Услуга потока
данных является услугой виртуальной цепи с подтверждением о приеме,
которая обеспечивает передачу сообщений неограниченных размеров.
Библиографическая справка
Протоколы Xerox Network Systems (XNS) разработаны корпорацией
Xerox в конце 1970-начале 1980 гг. Они предназначены для использования
в разнообразных средах передачи, процессорах и прикладных задачах офиса.
Несколько протоколов XNS похожи на Протокол Internet (IP) и Протокол
управления передачей (TCP), разработанных агентством DARPA для
Министерства обороны США (DoD). Информация по этим и связанным с
ними протоколам дается в
Главе 18 "".
Все
протоколы XNS соответствуют основным целям проектирования эталонной
модели OSI.
Благодаря своей доступности и раннему появлению на рынке, XNS был
принят большинством компаний, использовавших локальные сети с момента
их появления, в том числе компаниями Novell, Inc., Ungermann-Bass, Inc.
(которая теперь является частью Tandem Computers) и 3Com Corporation.
За время,прошедшее с тех пор, каждая из этих компаний внесла
различные изменения в протоколы XNS. Novell дополнила их
Протоколом доступа к услугам (Service access protocol - SAP), чтобы
обеспечить об'явление о ресурсах, и модифицировала протоколы Уровня 3
OSI (которые Novell переименовала в
Internetwork Packet Exchange - IPX -
Oбмен межсетевыми пакетами) для работы в сетях IEEE 802.3, а не
в сетях Ethernet. Ungermann-Bass модифицировала RIP для поддержания
задержки, а также числа пересылок. Были также внесены другие
незначительные изменения. С течением времени реализации XNS для
об'единенных в сети РС стали более популярными, чем XNS в том виде, в
котором они были первоначально разработаны компанией Xerox.
Доступ к среде
Несмотря на то, что в документации XNS упоминаются X.25, Ethernet и
HDLC, XNS не дает четкого определения того, что она называет
протоколом уровня 0. Также, как и многие другие комплекты протоколов,
XNS оставляет вопрос о протоколе доступа к носителю открытым, косвенным
образом позволяя любому такому протоколу выполнять главную роль в
транспортировке пакетов XNS через физический носитель.
Основы технологии
Несмотря на то, что они имеют общие цели проектирования, концепция XNS
о иерархии протоколов несколько отличается от той концепции, которую
предлагает эталонная модель OSI. На Рис. 22-1 показано приблизительное
сравнение XNS и эталонной модели OSI.
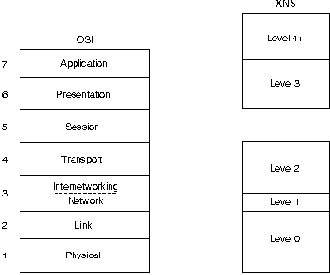
Как видно из Рис. 22-1, Xerox обеспечивает 5-уровневую модель передачи
пакетов. Уровень 0, который отвечает за доступ к каналу и манипуляцию
потока битов, примерно соответствует Уровням 1 и 2 OSI. Уровень 1
примерно соответствует той части Уровня 3 OSI, которая относится к
сетевому трафику. Уровень 2 примерно соответствует части Уровня 3,
которая связана с маршрутизацией в об'единенной сети, и Уровню 4 OSI,
который занимается связью внутри отдельных процессов. Уровни 3 и 4
примерно соответствуют двум верхним уровням модели OSI, которые
заняты структурированием данных, взаимодействием между отдельными
процессами и прикладными задачами. XNS не имеет протокола,
соответствующего Уровню 5 OSI (сеансовый уровень).
Протоколы высших уровней
XNS предлагает несколько протоколов высших уровней. Протокол
"Печатание" (Printing) обеспечивает услуги принтера. Протокол
"Ведение картотеки" (Filing) обеспечивает услуги доступа к файлам.
Протокол "Очистка9 (Сlearinghouse) обеспечивает услуги, связанные с
присвоением имени. Каждый из этих протоколов работает в дополнение
к протоколу "Курьер" (Сourier), который обеспечивает соглашения для
структурирования данных и взаимодействия процессов.
XNS также определяет протоколы уровня четыре. Это протоколы прикладного
уровня, но поскольку они имеют мало общего с фактическими функциями
связи, в спецификации XNS нет каких-либо определений по существу.
И наконец, протокол "Эхо" (Echo Protocol) используется для
тестирования
надежности узлов сети XNS. Он используется для поддержки таких функций,
как функции, обеспечиваемые командой ping, которую можно встретить в
Unix и других средах. Спецификация XNS описывает протокол "Эхо" как
протокол уровня два.
[]
[]
[]
Сетевой уровень
Протокол сетевого уровня XNS называется Протоколом дейтаграмм Internet
(Internet Datagram Protocol - IDP).
IDP выполняет стандартные функции Уровня 3, в число которых
входят логическая адресация и сквозная доставка дейтаграмм через
об'единенную сеть. Формат пакета IDP представлен на Рис. 22-2.

Первым полем в пакете IDP является 16-битовое поле контрольной суммы
(checksum), которое помогает проверить целостность пакета после его
прохождения через об'единенную сеть.
За полем контрольной суммы следует 16-битовое поле длины (length),
которое содержит информацию о полной длине (включая контрольную
сумму) текущей дейтаграммы.
За полем длины идет 8-битовое поле управления транспортировкой
(transport control) и 8-битовое поле типа пакета (packet type).
Поле
управления транспортировкой состоит из подполей числа пересылок
(hop count) и максимального времени существования пакета (maximum
packet lifetime - MPL). Значение подполя числа пересылок
устанавливается источником в исходное состояние 0 и инкрементируется на
1 при прохождении данной дейтаграммы через один роутер.
Когда значение поля числа пересылок доходит до 16, дейтаграмма
отвергается на основании допущения, что имеет место петля
маршрутизации. Подполе MPL содержит максимальное время (в секундах),
в течение которого пакет может оставаться в об'единенной сети.
За полем управления транспортировкой следует 8-битовое поле типа
пакета (packet type). Это поле определяет формат поля данных.
Каждый из адресов сети источника и назначения имеют три поля: 32-
битовый номер сети (network number), который уникальным образом
обозначает сеть в об'единенной сети, 48-битовый номер хоста
(host number), который является уникальным для
всех когда-либо выпущенных хостов, и 16-битовый
номер гнезда (socket number), который уникальным образом
идентифицирует гнездо (процесс) в пределах конкретнго хоста.
Адреса IEEE 802 эквивалентны номерам хостов,
поэтому хосты, подключенные более чем к одной
сети IEEE 802, имеют тот же самый адрес в каждом сегменте. Это делает
сетевые номера избыточными, но тем не менее полезными для
маршрутизации. Некоторые номера гнезд являются хорошо известными
(well-known); это означает, что услуга, выполняемая программным
обеспечением с использованием этих номеров гнезд, является статически
определенной. Все другие номера гнезд допускают многократное
использование.
XNS поддерживает пакеты с однопунктовой (из одного пункта в другой
пункт), многопунктовой и широковещательной адресацией. Многопунктовые
и широковещательные адреса далее делятся на 2 типа: прямые (directed)
и глобальные (global). Прямые многопунктовые адреса доставляют пакеты
членам группы многопунктовой адресации данной сети, заданной в адресе
сети назначения с многопунктовой адресацией. Прямые широковещательные
адреса доставляют пакеты всем членам заданной сети. Глобальные
многопунктовые адреса доставляют пакеты всем членам данной группы
в пределах всей об'единенной сети, в то время как глобальные
широковещательные адреса доставляют пакеты во все адреса об'единенной
сети. Один бит в номере хоста обозначает
отдельный адрес в противовес многопунктовому адресу. Все единицы в
поле хоста обозначают широковещательный адрес.
Для маршрутизации пакетов в об'единенной сети XNS использует схему
динамической маршрутизации, называемую Протоколом информации
маршрутизации (RIP). В настоящее время RIP является наиболее широко
используемым Протоколом внутренних роутеров (interior gateway
protocol - IGP) в сообществе Internet-среде международной сети,
обеспечивющей связность практически со всеми университетами и научно-
исследовательскими институтами, а также многими коммерческими
организациями в США. Подробная информация о RIP дается в
Главе 23 "".
Транспортный уровень
Функции транспортного уровня OSI реализуются несколькими протоколами.
Каждый из перечисленных ниже протоколов описан в спецификации ХNS как
протокол уровня два.
Протокол упорядоченной передачи пакетов
(Sequenced Packet Protocol - SPP)
обеспечивает надежную, с установлением соединения и управлением потока,
передачу пакетов от лица процессов клиента. По выполняемым функциям
он похож на протокол
из комплекта протоколов Internet и на
протокол
из комплекта протоколов OSI (смотри соответственно Главу
18 "" и
Главу "" 20).
Каждый пакет SPP включает в себя номер последовательности (sequence
number), который используется для упорядочивания пакетов и определения
тех из них, которые были скопированы или потеряны. Пакеты SPP
также содержат два 16-битовых идентификатора соединения (connection
identifier). Каждый конец соединения определяет один идентификатор
соединения. Оба идентификатора соединения вместе уникальным образом
идентифицируют логическое соединение между процессами клиента.
Длина пакетов SPP не может быть больше 576 байтов. Процессы клиента
могут согласовывать использование различных размеров пакетов во время
организации соединения, однако SPP не определяет характер такого
согласования.
Протокол обмена пакетами (Packet Exchange Protocol - PEP)
является протоколом типа запрос-ответ,
предназначенным обеспечивать надежность, которая больше надежности
простых услуг дейтаграмм (например, таких, которые обеспечивает IDP),
но меньше надежности SPP. По своим функциональным возможностям РЕР
аналогичен Протоколу дейтаграмм пользователя
()
из комплекта
протоколов Internet (смотри
Главу 18 "").
PEP
базируется на принципе одного пакета, обеспечивая повторные передачи,
но не обеспечивая выявление дублированных пакетов. Он полезен для
прикладных задач, в которых транзакции запрос-ответ являются
идемпотентными (повторяемыми без повреждения контекста), или в которых
надежная передача выполняется на другом уровне.
Протокол неисправностей (Error Protocol - EP) может быть использован
любым процессом клиента для уведомления другого процесса клиента о
том, что в сети имеет место ошибка. Например, этот протокол
используется в ситуациях, когда какая-нибудь реализация SPP
распознала дублированный пакет.
Библиографическая справка
Протокол Информации Маршрутизации (RIP) является протоколом
маршрутизации, который был первоначально разработан для Универсального
протокола PARC Xerox (где он назывался GWINFO) и использовался в
комплекте протоколов ХNS. RIP начали связывать как с UNIX, так и
с TCP/IP в 1982 г., когда версию UNIX, называемую Berkeley Standard
Distribution (BSD), начали отгружать с одной из реализацией RIP,
крторую называли "трассируемой" (routed)
(слово произносится "route
dee"). Протокол RIP, который все еще является очень популярным
протоколом маршрутизации в сообществе Internet, формально определен в
публикации "Протоколы транспортировки Internet" XNS (XNS Internet
Transport Protocols) (1981 г.) и в Запросах для комментария
(Request for Comments - RFC) 1058 (1988 г.).
RIP был повсеместно принят производителями персональных компьютеров
(РС) для использования в их изделиях передачи данных по сети.
Например, протокол маршрутизации AppleTalk (Протокол поддержания
таблицы маршрутизации - RTMP) является модернизированной версией RIP.
RIP также явился базисом для протоколов Novell, 3Com, Ungermann-Bass
и Banyan. RIP компаний Novell и 3Com в основном представляет собой
стандартный RIP компании Xerox. Ungermann-Bass и Banyan внесли
незначительные изменения в RIP для удовлетворения своих нужд.
Формат пакета (Реализация IP)
На Рис. 23-2 изображен формат пакета RIP для реализаций IP так, как
он определен в RFC 1058.
ПРИМЕЧАНИЕ:
На Рис. 23-2 представлен формат RIP, используемый для
сетей IP в Internet. В некоторые другие варианты RIP внесены
незначительные изменения формата и (или) имен файлов, которые
здесь перечислены, но функциональные возможности базового алгоритма
маршрутизации те же самые.

Первое поле в пакете RIP-это поле команд (command). Это поле содержит
целое число, обозначающее либо запрос, либо ответ. Команда "запрос"
запрашивает отвечающую систему об отправке всей таблицы маршрутизации
или ее части. Пункты назначения, для которых запрашивается ответ,
перечисляются далее в данном пакете. Ответная команда представляет
собой ответ на запрос или чаще всего какую-нибудь незатребованную
регулярную корректировку маршрутизации. Отвечающая система включает
всю таблицу маршрутизации или ее часть в ответный пакет. Регулярные
сообщения о корректировке маршрутизации включают в себя всю таблицу
мааршрутизации.
Поле версии (version) определяет реализуемую версию RIP. Т.к. в
об'единенной сети возможны многие реализации RIP, это поле может быть
использовано для сигнализирования о различных потенциально
несовместимых реализациях.
За 16-битовым полем, состоящим из одних нулей, идет поле идентификатора
семейства адресов (аddress family identifier). Это поле определяет
конкретное используемое семейство адресов. В сети Internet (крупной
международной сети, об'единяющей научно-исследовательские институты,
правительственные учреждения, университеты и частные предприятия) этим
адресным семейством обычно является IP (значение=2), но могут быть
также представлены другие типы сетей.
Следом за еще одним 16-битовым полем, состоящим из одних нулей, идет
32-битовое поле адреса (address). В реализациях RIP Internet это поле
обычно содержит какой-нибудь адрес IP.
За еще двумя 32-битовыми полями из нулей идет поле показателя RIP
(metric). Этот показатель представляет собой число пересылок (hop
count). Он указывает, сколько должно быть пересечено транзитных
участков (роутеров) об'единенной сети, прежде чем можно добраться
до пункта назначения.
В каждом отдельном пакете RIP IP допускается появление дo 25 вхождений
идентификатора семейства адреса, обеспечиваемых полями показателя.
Другими словами, в каждом отдельном пакете RIP может быть перечислено
до 25 пунктов назначения. Для передачи информации из более крупных
маршрутных таблиц используется множество пакетов RIP.
Как и другие протоколы маршрутизации, RIP использует определенные
таймеры для регулирования своей работы. Таймер корректировки
маршрутизации RIP (routing update timer) обычно устанавливается на
30 сек., что гарантирует отправку каждым роутером полной копии
своей маршрутной таблицы всем своим соседям каждые 30 секунд. Таймер
недействующих маршрутов (route invalid timer) определяет,
сколько должно
пройти времени без получения сообщений о каком-нибудь конкретном
маршруте, прежде чем он будет признан недействительным. Если какой-
нибудь маршрут признан недействительным, то соседи уведомяются об
этом факте. Такое уведомление должно иметь место до истечения времени
таймера отключения маршрута (route flush timer). Когда заданное время
таймера отключения маршрута истекает, этот маршрут удаляется из
таблицы маршрутизации. Типичные исходные значения для этих таймеров-
90 секунд для таймера недействующего маршрута и 270 секунд для таймера
отключения маршрута.
Формат таблицы маршрутизации
Каждая запись данных в таблице маршрутизации RIP обеспечивает
разнообразную информацию, включая конечный пункт назначения, следующую
пересылку на пути к этому пункту назначения и показатель (metric).
Показатель обозначает расстояние до пункта назначения, выраженное
числом пересылок до него. В таблице маршрутизации может находиться
также и другая информация, в том числе различные таймеры, связанные с
данным маршрутом. Типичная таблица маршрутизации RIP показана на
Рис. 23-1.
| Network A | Router 1 | 3 | t1, t2, t3 | x,y |
| Network B | Router 2 | 5 | t1, t2, t3 | x,y |
| Network C | Router 1 | 2 | t1, t2, t3 | x,y |
| . . . |
. . . |
. . . |
. . . |
. . . |
Figure 23-1
RIP поддерживает только самые лучшие маршруты к пункту назначения.
Если новая информация обеспечивает лучший маршрут, то эта информация
заменяет старую маршрутную информацию. Изменения в топологии сети
могут вызывать изменения в маршрутах, приводя к тому, например, что
какой-нибудь новый маршрут становится лучшим маршрутом до конкретного
пункта назначения. Когда имеют место изменения в топологии сети, то
эти изменения отражаются в сообщениях о корректировке маршрутизации.
Например, когда какой-нибудь роутер обнаруживает отказ одного из
каналов или другого роутера, он повторно вычисляет свои маршруты
и отправляет сообщения о корректировке маршрутизации. Каждый
роутер, принимающий сообщение об обновлении маршрутизации,
в котором содержится изменение, корректирует свои таблицы и
распространяет это изменение.
Характеристики стабильности
RIP определяет ряд характеристик, предназначенных для более стабильной
работы в условиях быстро изменяющейся топологии сети. В их число входит
ограничение числа пересылок, временные удерживания изменений
(hold-downs),
расщепленные горизонты (split-horizons) и корректировки отмены
(poison reverse updates).
Ограничение числа пересылок
RIP разрешает максимальное число пересылок, равное 15. Любому пункту
назначения, который находится дальше, чем на расстоянии 15 пересылок,
присваивается ярлык "недосягаемого".
Максимальное число пересылок RIP
в значительной мере ограничивает его применение в крупных
об'единенных сетях, однако способствует предотвращению появления
проблемы, называемой счетом до бесконечности (count to infinity),
приводящей к зацикливанию маршрутов в сети. Проблема счета до
бесконечности представлена на Рис. 23-3.
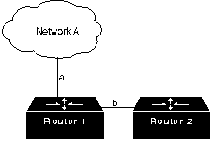
Рассмотрим, что случится, если на Рис. 23-3 канал Роутера 1
(R1) (канал а), связывающий его с сетью А, откажет. R1 проверяет свою
информацию и обнаруживает, что Роутер 2 (R2) связан с сетью А
каналом длиной в одну пересылку. Т.к. R1 знает, что он напрямую соединен
с R2, то он об'являет о маршруте из двух пересылок до сети А и начинает
направлять весь трафик в сеть А через R2. Это приводит к образованию
маршрутной петли. Когда R2 обнаруживает, что R1 может теперь достичь
сеть А за две пересылки, он изменяет запись своих собственных данных в
таблице маршрутизации, чтобы показать, что он имеет тракт длиной в 3
пересылки до сети А. Эта проблема, а также данная маршрутная петля
будут продолжаться бесконечно, или до тех пор, пока не будет навязано
какое-нибудь внешнее граничное условие. Этим граничным условием
является максимальное число пересылок RIP. Когда число пересылок
превысит 15, данный маршрут маркируется как недосягаемый. Через
некоторое время этот маршрут удаляется из таблицы.
Корректировки отмены маршрута
В то время как задачей расщепленных горизонтов является предотвращение
образования маршрутных петель между соседними роутерами,
корректировки отмены преданазначены для устранения более крупных
маршрутных петель. В основе их действия лежит положение о том, что
увеличение значения показателей маршрутизации обычно указывает на
наличие маршрутных петель. В этом случае отправляются корректировки
отмены для удаления данного маршрута и помещения его в состояние
временного удерживания.
[]
[]
[]
Расщепленные горизонты
Расщепленные горизонты используют преимущество того факта, что
никогда не бывает полезным отправлять информацию о каком-нибудь
маршруте обратно в том направлении, из которого пришла эта информация.
Для иллюстрации этого положения рассмотрим Рис. 23-4.

Pоутер 1 (R1) первоначально об'являет, что он располагает каким-
то маршрутом до Сети А. Pоутеру 2 (R2) нет оснований включать
этот маршрут в свою корректировку, отсылаемую обратно роутеру R1,
т.к. R1 ближе к Сети А. Правило расщепленного горизонта гласит, что
R2 должен исключить (попасть на) этот маршрут при любых корректировках, которые
он отправляет в R1.
Правило расщепленного горизонта помогает предотвратить маршрутные петли
между двумя узлами. Например, рассмотрим случай, когда отказывает
интерфейс R1 с Сетью А. При отсутствии расщепленных горизонтов R2
продолжает информировать R1 о том, что он может попасть в Сеть А через
R1. Если R1 не располагает достаточным интеллектом, то он действительно
может выбрать маршрут, предлагаемый R2, в качестве альтернативы для
своей отказавшей прямой связи, что приводит к образованию петли
маршрутизации. И хотя временное удерживание изменений должно
предотвращать это, применение расщепленного горизонта обеспечивает
дополнительную стабильность алгоритма.
Временные удерживания изменений
Временные удерживания изменений используются для того, чтобы помешать
регулярным сообщениям о корректировке незаконно восстановить в правах
маршрут, который оказался испорченным. Когда какой-нибудь маршрут
отказывает, соседние роутеры обнаруживают это. Затем они
вычисляют новые маршруты и отправляют сообщения об обновлении
маршрутизации, чтобы информировать своих соседей об изменениях в
маршруте. Эта деятельность приводит к появлению целой волны коррекций
маршрутизации, которые фильтруются через сеть.
Приведенные в действие корректировки неодновременно прибывают во все
устройства сети. Поэтому возможно, что какое-нибудь устройство,
которое еще не получило информацию о каком-нибудь отказе в сети, может
отправить регулярное сообщение о корректировке (в котором маршрут,
который только что отказал, все еще числится исправным) в другое
устройство, которое только что получило уведомление об этом отказе в
сети. В этом случае это другое устройство теперь будет иметь (и
возможно, рекламировать) неправильную маршрутную информацию.
Команды о временном удерживании указывают роутерам, чтобы они
на некоторое время придержали любые изменения, которые могут оказать
влияние на только что удаленные маршруты. Этот период удерживания
обычно рассчитывается таким образом, чтобы он был больше периода
времени, необходимого для внесения кокого-либо изменения о
маршрутизации во всю сеть. Удерживание изменений предотвращает
появление проблемы счета до бесконечности.
Библиографическая справка
Протокол маршрутизации внутренних роутеров (Interior Gateway
Routing Protokol-IGRP) является протоколом маршрутизации, разработанным
в середине 1980 гг. компанией Cisco Systems, Inc. Главной целью,
которую преследовала Cisco при разработке IGRP, было обеспечение
живучего протокола для маршрутизации в пределах автономной системы
(AS), имеющей произвольно сложную топологию и включающую в себя
носитель с разнообразными характеристиками ширины полосы и задержки.
AS является набором сетей, которые находятся под единым управлением
и совместно используют общую стратегию маршрутизации. Обычно AS
присваивается уникальный 16-битовый номер, который назначается
Центром Сетевой Информации (Network Information Center - NIC) Сети
Министерства Обороны (Defence Data Network - DDN).
В середине 1980 гг. самым популярным протоколом маршрутизации внутри
AS был Протокол Информации Маршрутизации (RIP). Хотя RIP был вполне
пригоден для маршрутизации в пределах относительно однородных
об'единенных сетей небольшого или среднего размера, его ограничения
сдерживали рост сетей. В частности, небольшая допустимая величина числа
пересылок (15) RIP ограничивала размер об'единенной сети, а его
единственный показатель (число пересылок) не обеспечивал достаточную
гибкость в сложных средах
(смотри Главу 23 ""). Популярность
роутеров Cisco и живучесть IGRP побудили многие организации,
которые имели крупные об'единенные сети, заменить RIP на IGRP.
Первоначальная реализация IGRP компании Cisco работала в сетях IP.
Однако IGRP был предназначен для работы в любой сетевой среде, и вскоре
Cisco распространила его для работы в сетях использующих Протокол Сет без
Установления Соединения (Connectionless Network Protocol - CLNP) OSI.
Формат пакета
Первое поле пакета IGRP содержит номер версии (version number). Этот
номер версии указывает на используемую версию IGRP и сигнализирует о
различных, потенциально несовместимых реализациях.
За полем версии идет поле операционного кода (opcode). Это поле
обозначает тип пакета. Операционный код, равный 1, обозначает пакет
корректировки; равный 2-пакет запроса. Пакеты запроса используются
источником для запроса маршрутной таблицы из другого роутера.
Эти пакеты состоят только из заголовка, содержащего версию,
операционный код и поля номера AS. Пакеты корректировки содержат
заголовок, за которым сразу же идут записи данных маршрутной таблицы.
На записи данных маршрутной таблицы не накладывается никаких
ограничений, за исключением того, что пакет не может превышать 1500
байтов, вместе с заголовком IP. Если этого недостаточно для того,
чтобы охватить весь об'ем маршрутной таблицы, то используются несколько
пакетов.
За полем операционного кода идет поле выпуска (edition). Это
поле содержит последовательный номер, который инкрементируется, когда
маршрутная таблица каким-либо образом изменяется. Это значение номера
выпуска используется для того, чтобы позволить роутерам избежать
обработки корректировок, содержащих информацию, которую они уже видели.
За полем выпуска идет поле, содержащее номер AS (AS number). Это
поле необходимо по той причине, что роутеры Cisco могут
перекрывать несколько AS. Несколько AS (или процессов IGRP) в одном
роутере хранят информацию маршрутизации AS отдельно.
Следующие три поля обозначают номер подсетей, номер главных сетей и
номер внешних сетей в пакете корректировки. Эти поля присутствуют
потому, что сообщения корректировки IGRP состоят из трех частей:
внутренней для данной подсети, внутренней для текущей AS и внешней
для текущей AS. Сюда включаются только подсети сети, связанной с тем
адресом, в который отправляется данная корректировка. Главные сети
(т.е. не подсети) помещаются во "внутреннюю для текущей AS" часть
пакета, если только они не помечены четко как внешние. Сети
помечаются как внешние, если информация о них поступает во внешней
части сообщения из другого роутера.
Последним полем в заголовке IGRP является поле контрольной суммы
(checksum). Это поле содержит какую-нибудь контрольную сумму для
заголовка IGRP и любую информацию корректировки, содержащуюся в данном
пакете. Вычисление контрольной суммы позволяет принимающему
роутеру проверять достоверность входящего пакета.
Сообщения о корректировке содержат последовательность из семи полей
данных для каждой записи данных маршрутной таблицы. Первое из этих
полей содержит три значащих байта адреса (address) (в случае
адреса IP). Следующие пять полей содержат значения показателей. Первое
из них обозначает задержку (delay), выраженную в десятках микросекунд.
Диапазон перекрывает значения от 10 мксек. до 167 сек. За полем
задержки следует поле ширины полосы (bandwidth). Ширина полосы
выражена в единицах 1 Кбит/сек и перекрывает диапазон от линии
с шириной полосы 1200 бит/сек до 10 Гбит/сек. Затем идет поле MTU,
которое обеспечивет размер MTU в байтах. За полем MTU идет поле
надежности (reliability), указывающее процент успешно переданных и
принятых пакетов. Далее идет поле нагрузки (load), которое обозначает
занятую часть канала в процентном отношении. Последним полем в каждой
записи данных маршрутизации является поле числа пересылок (hop count).
И хотя использование числа пересылок не явно выражено при определении
показателя, тем не менее это поле содержится в пакете IGRP и
инкрементируется после обработки пакета, обеспечивая использование
подсчета пересылок для предотвращения петель.
IGRP обладает рядом характеристик, предназначенных для повышения
своей стабильности. В их число входят временное удерживание изменений,
расщепленные горизонты и корректировки отмены.
Временные удерживания изменений
Временное удерживание изменений используется для того, чтобы помешать
регулярным сообщениям о коррректировке незаконно восстановить
в правах маршрут, который возможно был испорчен. Когда какой-нибудь
роутер выходит из строя, соседние роутеры обнаруживают это
через отсутствие регурярного поступления запланированных сообщений.
Далее эти роутеры вычисляют новые маршруты и отправляют сообщения
о корректировке маршрутизации, чтобы информировать своих соседей о
данном изменении маршрута. Результатом этой деятельности является
запуск целой волны корректировок, которые фильтруются через сеть.
Приведенные в действие корректировки поступают в каждое сетевое
устройство не одновременно. Поэтому возможно, что какое-нибудь
устройство, которое еще не было оповещено о неисправности в сети,
может отправить регулярное сообщение о корректировке (указывающее, что
какой-нибудь маршрут, который только что отказал, все еще считается
исправным) в другое устройство, которое только что получило уведомление
о данной неисправности в сети. В этом случае последнее устройство будет
теперь содержать (и возможно, рекламировать) неправильную информацию
о маршрутизации.
Команды о временном удерживании изменений предписывают роутерам
удерживать в течение некоторого периода времени любые изменения,
которые могут повлиять на маршруты. Период удерживания изменений
обычно рассчитывается так, чтобы он был больше периода времени,
необходимого для корректировки всей сети в соответствии с каким-либо
изменением маршрутизации.
Корректировки отмены маршрута
В то время как расщепленные горизонты должны препятствовать
зацикливанию маршрутов между соседними роутерами, корректировки
отмены маршрута предназначены для борьбы с более крупными маршрутными
петлями. Увеличение значений показателей маршрутизации обычно указывает
на появление маршрутных петель. В этом случае посылаются корректировки
отмены, чтобы удалить этот маршрут и перевести его в состояние
удерживания. В реализации IGRP компании Cisco корректировки отмены
отправляются в том случае, если показатель маршрута увеличивается на
коэффициент 1.1 или более.
Расщепленные горизонты
Понятие о расщепленных горизонтах проистекает из того факта, что
никогда не бывает полезным отправлять информацию о каком-нибудь
маршруте обратно в том направлении, из которого она пришла. Для
иллюстрации этого положения рассмотрим Рис. 24-2.
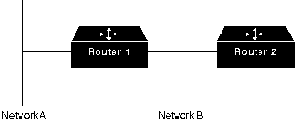
Роутер 1 (R1) первоначально об'являет, что у него есть какой-то
маршрут до Сети А. Роутеру 2 (R2) нет оснований включать этот
маршрут в свою корректировку, отправляемую в R1, т.к. R1 ближе к
Сети А. В правиле о расщепленных горизонтах говорится, что R2 должен
исключить этот маршрут независимо от того, какие корректировки он
отправляет в R1.
Правило о расщепленных горизонтах помогает предотвращать
зацикливание маршрутов. Например, рассмотрим случай, когда интерфейс R1
с Сетью А отказывает. Без расщепленных горизонтов R2 продолжал бы
информировать R1, что он может попасть в Сеть А (через R1!). Если R1
не располагает достаточным интеллектом, он действительно может выбрать
маршрут, предлагаемый R2, в качестве альтернативы своему отказавшему
прямому соединению, что приводит к образованию маршрутной петли. И хотя
удерживание изменений должно помешать этому, в IGRP реализованы также
расщепленные горизонты, т.к. они обеспечивают дополнительную
стабильность алгоритма.
Таймеры
IGRP обеспечивает ряд таймеров и переменных, содержащих временные
интервалы. Сюда входят таймер корректировки, таймер недействующих
маршрутов, период времени удерживания изменений и таймер отключения.
Таймер корректировки определяет, как часто должны отправляться
сообщения о корректировке маршрутов. Для IGRP значение этой
переменной, устанавливаемое по умолчанию, равно 90 сек. Таймер
недействующих маршрутов определяет, сколько времени должен ожидать
роутер при отсутствии сообщений о корректировке какого-нибудь
конкретного маршрута, прежде чем об'явить этот маршрут недействующим.
Время по умолчанию IGRP для этой переменной в три раза превышает период
корректировки. Переменная величина времени удерживания определяет
промежуток времени удерживания. Время по умолчанию IGRP для этой
переменной в три раза больше периода таймера корректировки, плюс
10 сек. И наконец, таймер отключения указывает, сколько времени
должно пройти прежде, чем какой-нибудь роутер должен быть
исключен из маршрутной таблицы. Время по умолчанию IGRP для этой
величины в семь раз превышает период корректировки маршрутизации.
[]
[]
[]
Технология
IGRP является протоколом внутренних роутеров (IGP) с вектором
расстояния. Протоколы маршрутизации с вектором расстояния требуют от
каждого роутера отправления через определенные интервалы времени
всем соседним роутерам всей или части своей маршрутной
таблицы в сообщениях о корректировке маршрута. По мере того, как
маршрутная информация распространяется по сети, роутеры могут
вычислять расстояния до всех узлов об'единенной сети.
Протоколы маршрутизации с вектором расстояния часто противопоставляют
протоколам маршрутизации с указанием состояния канала, которые
отправляют информацию о локальном соединении во все узлы об'единенной
сети. Рассмотрение двух популярных протоколов, использующих алгоритм
маршрутизации с указанием состояния канала, "Открытый протокол с
алгоритмом поиска наикратчайшего пути" (Open Shortest Path First) и
"Промежуточная система-Промежуточная система" (Intermediate System to
Intermediate System (IS-IS)), дается соответственно в
Главе 25 ""
и Главе 28 "".
IGRP использует комбинацию (вектор) показателей. Задержка об'единенной
сети (internetwork delay), ширина полосы (bandwidth), надежность
(reliability) и нагрузка (load) - все эти показатели
учитываются в виде
коэффициентов при принятии маршрутного решения. Администраторы сети
могут устанавливать факторы весомости для каждого из этих показателей.
IGRP использует либо установленные администратором, либо
устанавливаемые по умолчанию весомости для автоматического расчета
оптимальных маршрутов.
IGRP предусматривает широкий диапазон значений для своих показателей.
Например, надежность и нагрузка могут принимать любое значение в
интервале от 1 до 255, ширина полосы может принимать значения,
отражающие скорости пропускания от 1200 до 10 гигабит в секунду, в то
время как задержка может принимать любое значение от 1-2 до 24-го
порядка. Широкие диапазоны значений показателей позволяют производить
удовлетворительную регулировку показателя в об'единенной сети с большим
диапазоном изменения характеристик производительности. Самым важным
является то, что компоненты показателей об'единяются по алгоритму,
который определяет пользователь. В результате администраторы сети могут
оказывать влияние на выбор маршрута, полагаясь на свою интуицию.
Для обеспечения дополнительной гибкости IGRP разрешает многотрактовую
маршрутизацию. Дублированные линии с одинаковой шириной полосы могут
пропускать отдельный поток трафика циклическим способом с
автоматическим переключением на вторую линию, если первая линия
выходит из строя. Несколько трактов могут также использоваться даже
в том случае, если показатели этих трактов различны. Например, если
один тракт в три раза лучше другого благодаря тому, что его показатели
в три раза ниже, то лучший тракт будет использоваться в три раза чаще.
Только маршруты с показателями, которые находятся в пределах
определенного диапазона показателей наилучшего маршрута, используются
для многотрактовой маршрутизации.
Алгоритм SPF
Алгоритм маршрутизации SPF является основой для операций OSPF. Когда
на какой-нибудь роутер SPF подается питание, он инициилизирует
свои структуры данных о протоколе маршрутизации, а затем ожидает
индикации от протоколов низшего уровня о том, что его интерфейсфы
работоспособны.
После получения подтверждения о работоспособности своих интерфейсов
роутер использует приветственный протокол (hello protocol) OSPF,
чтобы приобрести соседей (neighbor). Соседи - это роутеры с
интерфейсами с общей сетью. Описываемый роутер отправляет своим
соседям приветственные пакеты и получает от них такие же пакеты.
Помимо оказания помощи в приобретении соседей, приветственные пакеты
также действуют как подтверждение дееспособности, позволяя другим
роутерам узнавать о том, что другие роутери все еще
функционируют.
В сетях с множественным доступом (multi-access networks)
(сетях, поддержиающих более одного роутера),
протокол Hello выбирает назначенный
роутер (designated router) и дублирующий назначенный
роутер. Назначеный роутер, помимо других функций, отвечает
за генерацию LSA для всей сети с множественным доступом. Назначенные
роутеры позволяют уменьшить сетевой трафик и об'ем топологической
базы данных.
Если базы данных о состоянии канала двух роутеров являются
синхронными, то говорят, что эти роутеры смежные (adjacent). В
сетях с множественным доступом назначенные роутеры определяют,
какие роутеры должны стать смежными. Топологические базы данных
синхронизируются между парами смежных роутеров. Смежности
управляют распределением пакетов протокола маршрутизации. Эти пакеты
отправляются и принимаются только на смежности.
Каждый роутер периодическив отправляет какое-нибудь LSA. LSA
также отправляются в том случае, когда изменяется состояние какого-
нибудь роутера. LSA включает в себя информацию о смежностях
роутера. При сравнении установленных смежностей с состоянием
канала быстро обнаруживаются отказавшие роутеры, и топология
сети изменяется сооответствующим образом. Из топологической базы
данных, генерируемых LSA, каждый роутер рассчитывает дерево
наикратчайшего пути, корнем которого является он сам. В свою очередь
дерево наикратчайшего пути выдает маршрутную таблицу.
Библиографическая справка
Открытый протокол, базирующийся на алгоритме поиска наикратчайшего
пути (Open Shortest Path Fisrt - OSPF) является протоколом маршрутизации,
разработанным для сетей IP рабочей группой Internet Engineering Task
Force (IETF), занимающейся разработкой протоколов для внутрисистемных
роутеров (interior gateway protocol - IGP). Рабочая группа была
образована в 1988 г. для разработки протокола IGP, базирующегося на
алгоритме "поиска наикратчайшего пути"
(shortest path first - SPF), с
целью его использования в Internet, крупной международной сети,
об'единяющей научно-исследовательские институты, правительственные
учреждения, университеты и частные предприятия. Как и протокол IGRP
(смотри Главу 24 ""),
OSPF был разработан по той причине, что к
середине 1980 гг. непригодность RIP для обслуживания крупных
гетерогенных об'единенных систем стала все более очевидна
(смотри Главу 23 "").
ОSPF явился результатом научных исследований по нескольким
направлениям, включающим:
Алгоритм SPF компании Bolt, Beranek и Newman (BBN), разработанный
для Arpanet (программы с коммутацией пакетов, разработанной BBN в
начале 1970 гг., которая явилась поворотным пунктом в истории
разработки сетей) в 1978 г.
Исследования Koмпании Radia Perlman по отказоустойчивости широкой
рассылки маршрутной информации (1988).
Исследования BBN по маршрутизации в отдельной области (1986).
Одна из первых версий протокола маршрутизации IS-IS OSI
(Информация о IS-IS дается в
Главе 28 "").
Как видно из его названия, OSPF имеет две основных характеристики.
Первая из них-это то, что протокол является открытым, т.е. его
спецификация является общественным достоянием. Спецификация OSPF
опубликована в форме Запроса для Комментария (RFC) 1247. Второй его
главной характеристикой является то, что он базируется на алгоритме
SPF. Алгоритм SPF иногда называют алгоритмом Dijkstra по имени автора,
который его разработал.
Дополнительные характеристики OSPF
В числе дополнительных характеристик OSRF - равные затраты,
многотрактовая маршрутизация (multipath routing)
и маршрутизация, базирующаяся на запросах
типа услуг высшего уровня (type of service - TOS).
Базирующаяся на TOS
маршрутизация поддерживает те протоколы высшего уровня, которые могут
назначать конкретные типы услуг. Например, какая-нибудь прикладная
программа может включить требование о том, что определенная информация
является срочной. Если OSPF имеет в своем распоряжении каналы с высоким
приоритетом, то они могут быть использованы для транспортировки срочных
дейтаграмм.
OSPF обеспечивает один или более показателей. Если используется только
один показатель, то он считается произвольным, и TOS не обеспечивается.
Если используется более одного показателя, то TOS обеспечивается
факультативно путем использования отдельного показателя (и
следовательно, отдельной маршрутной таблицы) для каждой из 8
комбинаций, образованной тремя битами IP TOS: битом задержки (delay),
производительности (throughput) и надежности (reliability).
Например,
если биты IP TOS задают небольшую задержку, низкую производительность
и высокую надежность, то OSPF вычисляет маршруты во все пункты
назначения, базируясь на этом обозначении TOS.
Маски подсети IP включаются в каждый об'явленный пункт назначения,
что позволяет использовать маски подсети переменной длины
(variable-length subnet masks).
С помощью масок подсети переменной длины сеть IP
может быть разбита на несколько подсетей разной величины. Это
обеспечивает администраторам сетей дополнительную гибкость при выборе
конфигурации сети.
[]
[]
[]
Формат пакета
Все пакеты OSPF начинаются с 24-байтового заголовка, как показано
на Рис. 25-2.

Первое поле в заголовке OSPF - это номер версии OSPF (version number).
Номер версии обозначает конкретную используемую реализацию OSPF.
За номером версии идет поле типа (type). Существует 5 типов пакета
OSPF:
Hello.
Отправляется через регулярные интервалы времени для
установления и поддержания соседских взаимоотношений.
Database Description.
Описание базы данных. Описывает содержимое базы данных;
обмен этими пакетами производится при инициализации смежности.
Link-State Request
Запрос о состоянии канала. Запрашивает
части топологической базы данных соседа. Обмен этими пакетами
производится после того, как какой-нибудь роутер обнаруживает,
(путем проверки пакетов описания базы данных), что часть его
топологической базы данных устарела.
Link-State Update
Корректировка состояния канала. Отвечает на
пакеты запроса о состоянии канала. Эти пакеты также используются для
регулярного распределения LSA. В одном пакете могут быть включены
несколько LSA.
Link-State Acknowledgement
Подтверждение состояния канала.
Подтверждает пакеты корректировки состояния канала. Пакеты
корректировки состояния канала должны быть четко подтверждены, что
является гарантией надежности процесса лавинной адресации пакетов
корректировки состояния канала через какую-нибудь область.
Каждое LSA в пакете корректировки состояния канала содержит тип поля.
Существуют 4 типа LSA:
Router links advertisements (RLA)
Об'явления о каналах роутера.
Описывают собранные данные о состоянии каналов
роутера, связывающих его с конкретной областью. Любой
роутер отправляет RLA для каждой области, к которой он
принадлежит. RLA направляются лавинной адресацией через всю область,
но они не отправляются за ее пределы.
Network links advertisements (NLA)
Об'явления о сетевых каналах.
Отправляются назначенными роутерами. Они описывают все
роутеры, которые подключены к сети с множественным доступом, и
отправляются лавинной адресацией через область, содержащую
данную сеть с множественным доступом.
Summary links advertisements (SLA)
Суммарные об'явления о каналах.
Суммирует маршруты к пунктам назначения, находящимся вне какой-либо
области, но в пределах данной AS. Они генерируются роутерами
границы области, и отправляются лавинной адресацией через данную
область. В стержневую область посылаются об'явления только о
внутриобластных роутерах. В других областях рекламируются как
внутриобластные, так и межобластные маршруты.
AS external links advertisements
Об'явления о внешних каналах AS.
Описывают какой-либо маршрут к одному из пунктов назначения, который
является внешним для данного AS. Об'явления о внешних каналах AS
вырабатываются граничными роутерами AS. Этот тип об'явлений
является единственным типом об'явлений, которые продвигаются во всех
направлениях данной AS; все другие об'явления продвигаются только в
пределах конкретных областей.
За полем типа заголовка пакета OSPF идет поле длины пакета (packet
length). Это поле обеспечивает длину пакета вместе с заголовком OSPF
в байтах.
Поле идентификатора роутера (router ID) идентифицирует источник
пакета.
Поле идентификатора области (area ID) идентифицирует область, к которой
принадлежит данный пакет. Все пакеты OSPF связаны с одной отдельной
областью.
Стандартное поле контрольной суммы IP (checksum) проверяет содержимое
всего пакета для выявления потенциальных повреждений, имевших место при
транзите.
За полем контрольной суммы идет поле типа удостоверения (authentication
type). Примером типа удостоверения является "простой пароль".
Все обмены протокола OSPF проводятся с установлением достоверности. Тип
удостоверения устанавливается по принципу "отдельный для каждой
области".
За полем типа удостоверения идет поле удостоверения (authentication).
Это поле длиной 64 бита и содержит информацию удостоверения.
Иерархия маршрутизации
В отличие от RIP, OSPF может работать в пределах некоторой
иерархической системы. Самым крупным об'ектом в этой иерархии является
автономная система (Autonomous System - AS)
AS является набором сетей, которые находятся
под единым управлением и совместно используют общую стратегию
маршрутизации. OSPF является протоколом маршрутизации внутри AS, хотя
он и способен принимать маршруты из других AS и отправлять маршруты в
другие AS.
Любая AS может быть разделена на ряд областей (area).
Область - это группа
смежных сетей и подключенных к ним хостов.
Роутеры, имеющие несколько интерфейсов, могут участвовать в
нескольких областях. Такие роутеры, которые называются
роутерами границы областей (area border routers),
поддерживают отдельные топологические
базы данных для каждой области.
Топологическая база (topological database)
данных фактически представляет собой общую картину
сети по отношению к роутерам. Топологическая база данных содержит
набор LSA, полученных от всех роутеров, находящихся в одной
области. Т.к. роутеры одной области коллективно пользуются одной
и той же информацией, они имеют идентичные топологические базы данных.
Термин "домен" (domain) исользуется для описания части сети,
в которой
все роутери имеют идентичную топологическую базу данных. Термин
"домен" часто используется вместо AS.
Топология области является невидимой для об'ектов, находящихся вне этой
области. Путем хранения топологий областей отдельно, OSPF добивается
меньшего трафика маршрутизации, чем трафик для случая, когда AS не
разделена на области.
Разделение на области приводит к образованию двух различных типов
маршрутизации OSPF, которые зависят от того, находятся ли источник и
пункт назначения в одной и той же или разных областях. Маршрутизация
внутри области имеет место в том случае, когда источник и пункт
назначения находятся в одной области; маршрутизация между областями -
когда они находятся в разных областях.
Стержневая часть OSPF (backbone) отвечает за распределение маршрутной
информации между областями. Она включает в себя все роутеры
границы области, сети, которые не принадлежат полностью како-либо из
областей, и подключенные к ним роутеры. На Рис. 25-1 представлен
пример об'единенной сети с несколькими областями.
На этом рисунке роутеры 4, 5, 6, 10, 11 и 12 образуют стержень.
Если хост Н1 Области 3 захочет отправить
пакет хосту Н2 Области 2, то пакет отправляется
в роутер 13, который продвигает его в роутер 12, который в
свою очередь отправляет его в роутер 11. Роутер 11
продвигает пакет вдоль стержня к роутеру 10 границы области,
который отправляет пакет через два внутренних роутера этой
области (роутеры 9 и 7) до тех пор, пока он не будет продвинут
к хосту Н2.
Сам стержень представляет собой одну из областей OSPF, поэтому все
стержневые роутеры используют те же процедуры и алгоритмы
поддержания маршрутной информации в пределах стержневой области,
которые используются любым другим роутером. Топология стержневой
части невидима для всех внутренних роутеров точно также, как
топологии отдельных областей невидимы для стержневой части.
Область может быть определена таким образом, что стержневая часть не
будет смежной с ней. В этом случае связность стержневой части должна
быть восстановлена через виртуальные соединения. Виртуальные соединения
формируются между любыми роутерами стержневой области, которые
совместно используют какую-либо связь с любой из нестержневых областей;
они функционируют так, как если бы они были непосредственными связями.
Граничные роутеры AS, использующие OSPF, узнают о внешних
роутерах через протоколы внешних роутеров (EGPs), таких, как
Exterior Gateway Protocol (EGP) или
Border Gateway Protocol (BGP),
или через информацию о конфигурации (информация об этих протоколах
дается соответственно в
Главе 26 "" и
Главе 27 "").
Основы технологии
OSPF является протоколом маршрутизации с об'явлением состояния о канале
(link-state). Это значит, что он требует отправки об'явлений о
состоянии канала (link-state advertisement - LSA) во все роутеры,
которые находятся в пределах одной и тойже иерархической области. В
oб'явления LSA протокола OSPF включается информация о подключенных
интерфейсах, об использованных показателях и о других переменных. По
мере накопления роутерами OSPF информации о состоянии канала,
они используют алгоритм SPF для расчета наикратчайшего пути к каждому
узлу.
Являясь алгоритмом с об'явлением состояния канала, OSPF отличается от
RIP и IGRP, которые являются протоколами маршрутизации с вектором
расстояния. Роутеры, использующие алгоритм вектора расстояния,
отправляют всю или часть своей таблицы маршрутизации в сообщения о
корректировке маршрутизации, но только своим соседям.